使用 Azure 数据工厂或 Synapse Analytics 复制和转换 Microsoft Fabric 仓库中的数据
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
提示
试用 Microsoft Fabric 中的数据工厂,这是一种适用于企业的一站式分析解决方案。 Microsoft Fabric 涵盖从数据移动到数据科学、实时分析、商业智能和报告的所有内容。 了解如何免费开始新的试用!
本文概述了如何使用复制活动从/向 Microsoft Fabric 仓库复制数据。 有关详细信息,请阅读 Azure 数据工厂或 Azure Synapse Analytics 的简介文章。
支持的功能
以下功能支持此 Microsoft Fabric 仓库连接器:
| 支持的功能 | IR | 托管专用终结点 |
|---|---|---|
| 复制活动(源/接收器) | ① ② | ✓ |
| 映射数据流源(源/接收器) | ① | ✓ |
| Lookup 活动 | ① ② | ✓ |
| GetMetadata 活动 | ① ② | ✓ |
| 脚本活动 | ① ② | ✓ |
| 存储过程活动 | ① ② | ✓ |
① Azure 集成运行时 ② 自承载集成运行时
开始使用
若要使用管道执行复制活动,可以使用以下工具或 SDK 之一:
使用 UI 创建 Microsoft Fabric 仓库链接服务
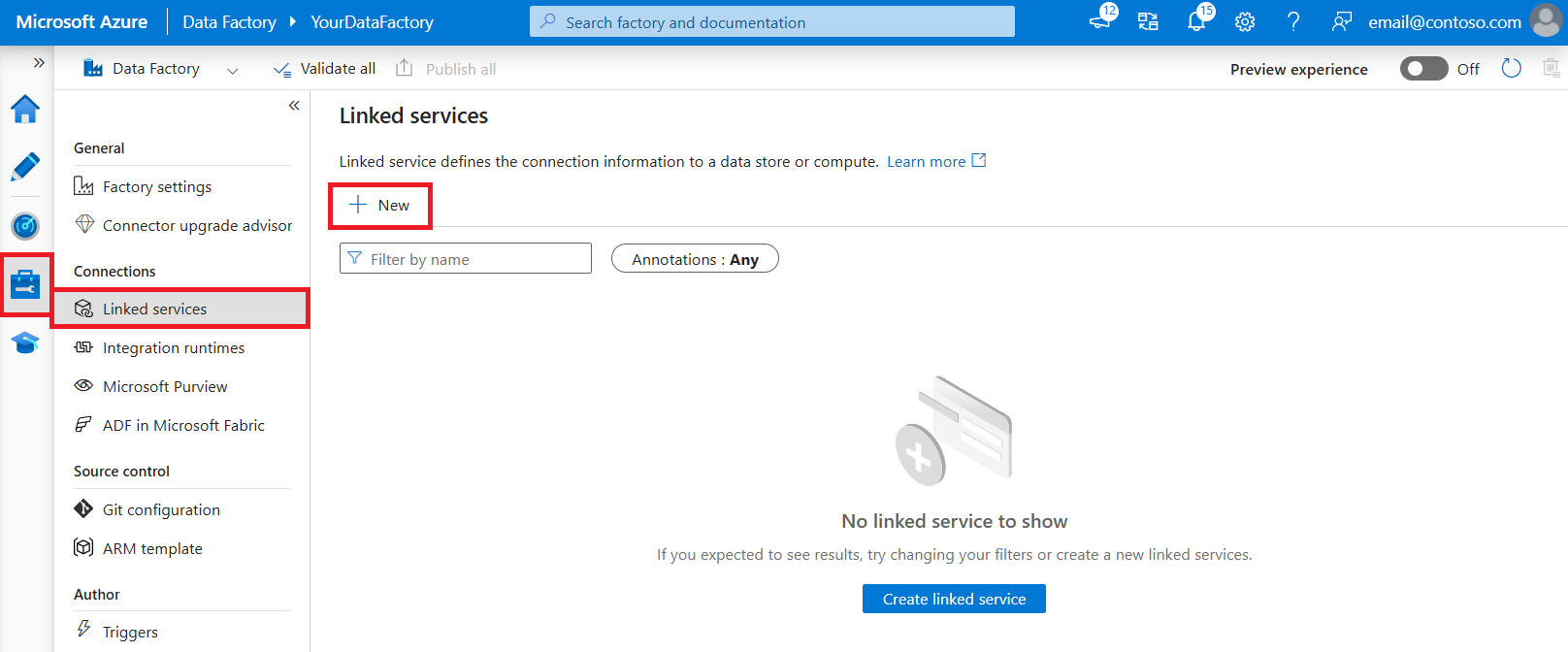
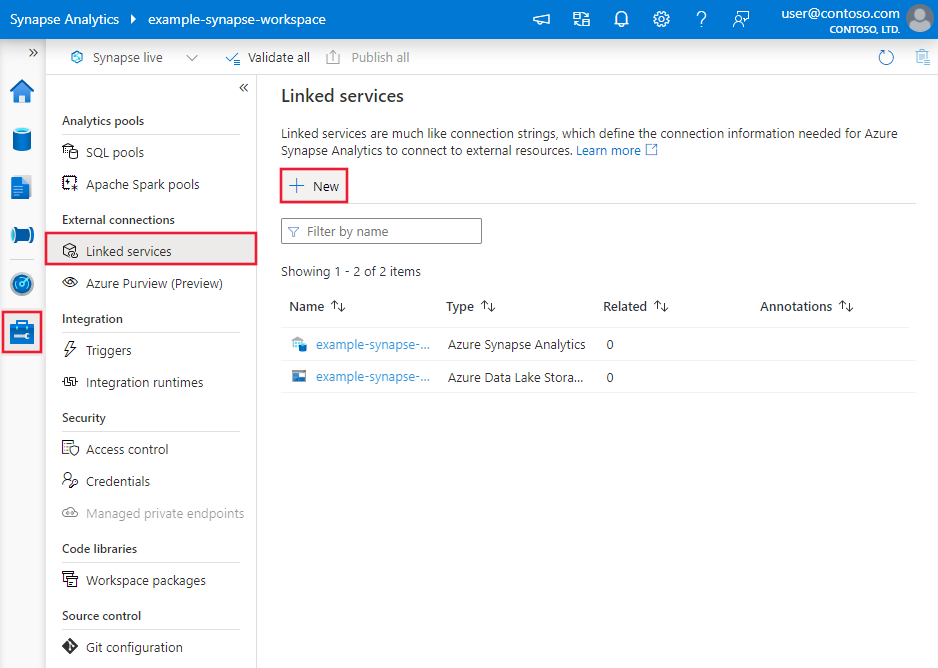
使用以下步骤在 Azure 门户 UI 中创建 Microsoft Fabric 仓库链接服务。
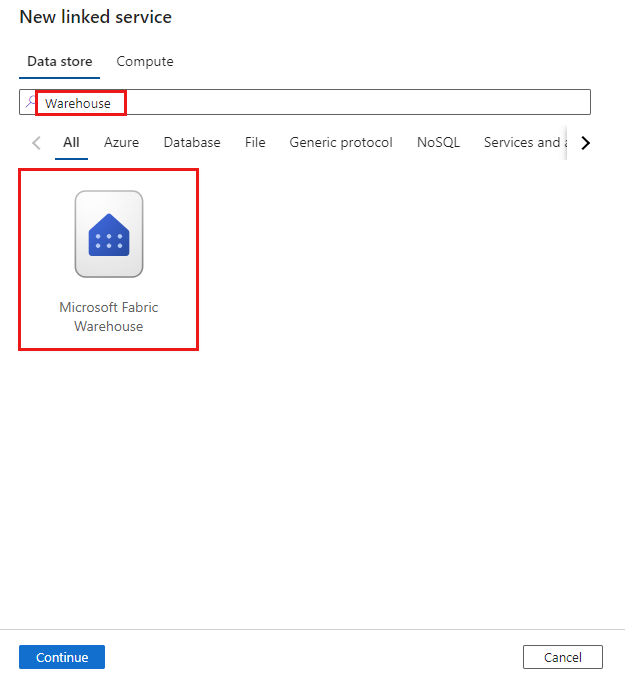
浏览到 Azure 数据工厂或 Synapse 工作区中的“管理”选项卡,并选择“链接服务”,然后选择“新建”:
搜索仓库并选择连接器。
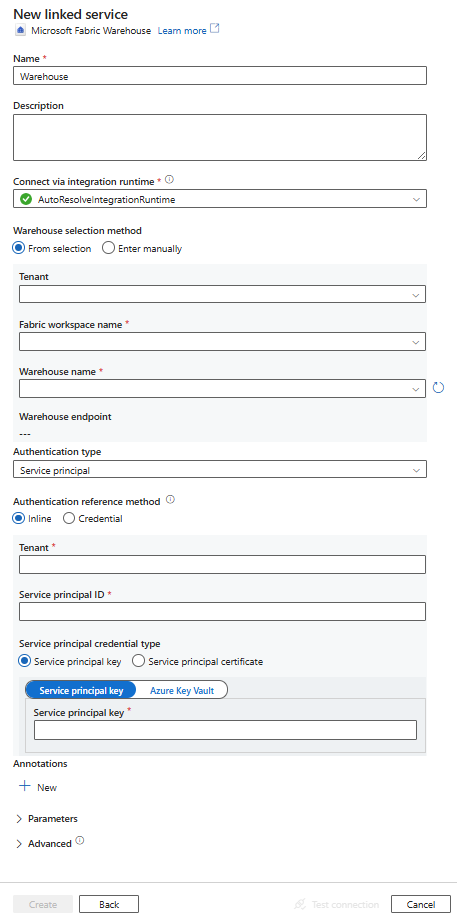
配置服务详细信息、测试连接并创建新的链接服务。
连接器配置详细信息
以下部分提供有关用于定义特定于 Microsoft Fabric 仓库的 Azure 数据工厂实体的属性的详细信息。
链接服务属性
Microsoft Fabric 仓库连接器支持以下身份验证类型。 请参阅相应部分的了解详细信息:
服务主体身份验证
若要使用服务主体身份验证,请按照以下步骤操作。
将应用程序注册到 Microsoft 标识平台并添加客户端密码。 之后,记下以下值,这些值用于定义链接服务:
- 应用程序(客户端)ID,它是链接服务中的服务主体 ID。
- 客户端密码值,它是链接服务中的服务主体密钥。
- 租户 ID
至少向服务主体授予 Microsoft Fabric 工作区中的“参与者”角色。 执行以下步骤:
转到 Microsoft Fabric 工作区,选择顶部栏上的“管理访问”。 然后选择“添加人员或组”。
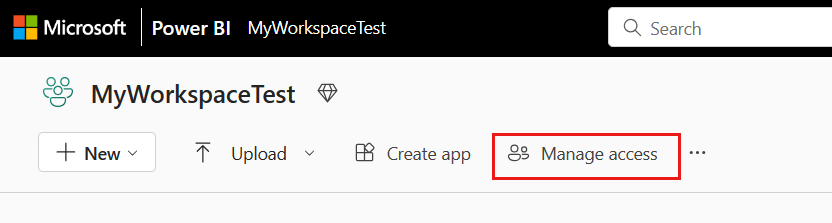
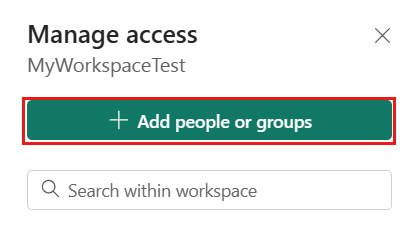
在“添加人员”窗格中,输入服务主体名称,然后从下拉列表中选择服务主体。
将角色指定为“参与者”或更高级别角色(管理员、成员),然后选择“添加”。
服务主体显示在“管理访问”窗格上。
链接服务支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | type 属性必须设置为“仓库”。 | 是 |
| endpoint | Microsoft Fabric 仓库服务器的终结点。 | 是 |
| workspaceId | Microsoft Fabric 工作区 ID。 | 是 |
| artifactId | Microsoft Fabric 仓库对象 ID。 | 是 |
| tenant | 指定应用程序的租户信息(域名或租户 ID)。 将鼠标悬停在 Azure 门户右上角进行检索。 | 是 |
| servicePrincipalId | 指定应用程序的客户端 ID。 | 是 |
| servicePrincipalCredentialType | 要用于服务主体身份验证的凭据类型。 允许的值为“ServicePrincipalKey”和“ServicePrincipalCert”。 | 是 |
| servicePrincipalCredential | 服务主体凭据。 使用“ServicePrincipalKey”作为凭据类型时,请指定应用程序的客户端密码值。 将此字段标记为 SecureString 以安全地存储它,或引用存储在 Azure Key Vault 中的机密。 当使用 ServicePrincipalCert 作为凭据时,请引用 Azure Key Vault 中的证书并确保证书内容类型为 PKCS #12。 |
是 |
| connectVia | 用于连接到数据存储的集成运行时。 可使用 Azure Integration Runtime 或自承载集成运行时(如果数据存储位于专用网络)。 如果未指定,则使用默认 Azure Integration Runtime。 | 否 |
示例:使用服务主体密钥身份验证
也可以将服务主体密钥存储在 Azure Key Vault 中。
{
"name": "MicrosoftFabricWarehouseLinkedService",
"properties": {
"type": "Warehouse",
"typeProperties": {
"endpoint": "<Microsoft Fabric Warehouse server endpoint>",
"workspaceId": "<Microsoft Fabric workspace ID>",
"artifactId": "<Microsoft Fabric Warehouse object ID>",
"tenant": "<tenant info, e.g. *.partner.onmschina.cn>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
数据集属性
有关可用于定义数据集的各部分和属性的完整列表,请参阅数据集一文。
Microsoft Fabric 仓库数据集支持以下属性:
| properties | 描述 | 必需 |
|---|---|---|
| type | 数据集的“type”属性必须设置为“WarehouseTable”。 | 是 |
| schema | 架构的名称。 | 对于源为“No”,对于接收器为“Yes” |
| 表 | 表/视图的名称。 | 对于源为“No”,对于接收器为“Yes” |
数据集属性示例
{
"name": "FabricWarehouseTableDataset",
"properties": {
"type": "WarehouseTable",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Warehouse linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring >
],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
复制活动属性
要完整了解可供活动定义使用的各个部分和属性,请参阅复制活动配置和管道和活动。 本部分提供 Microsoft Fabric 仓库源和接收器支持的属性列表。
作为源的 Microsoft Fabric 仓库
提示
若要详细了解如何使用数据分区从 Microsoft Fabric 仓库高效加载数据,请参阅从 Microsoft Fabric 仓库进行并行复制。
若要从 Microsoft Fabric 仓库复制数据,请将复制活动源中的 type 属性设置为 WarehouseSource。 复制活动 source 节支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | 复制活动源的“type”属性必须设置为“WarehouseSource”。 | 是 |
| sqlReaderQuery | 使用自定义 SQL 查询读取数据。 示例:select * from MyTable。 |
否 |
| sqlReaderStoredProcedureName | 从源表读取数据的存储过程的名称。 最后一个 SQL 语句必须是存储过程中的 SELECT 语句。 | 否 |
| storedProcedureParameters | 存储过程的参数。 允许的值为名称或值对。 参数的名称和大小写必须与存储过程参数的名称和大小写匹配。 |
否 |
| queryTimeout | 指定查询命令执行的超时值。 默认值为 120 分钟。 | 否 |
| isolationLevel | 指定 SQL 源的事务锁定行为。 允许的值为“Snapshot”。 如果未指定,则使用数据库的默认隔离级别。 有关详细信息,请参阅 system.data.isolationlevel。 | 否 |
| partitionOptions | 指定用于从 Microsoft Fabric 仓库加载数据的数据分区选项。 允许的值为:“None”(默认值)和“DynamicRange”。 启用分区选项(即,该选项不为 None)时,用于从 Microsoft Fabric 仓库并行加载数据的并行度由复制活动上的 parallelCopies 设置控制。 |
否 |
| partitionSettings | 指定数据分区的设置组。 当分区选项不是 None 时适用。 |
否 |
在 partitionSettings 下: |
||
| partitionColumnName | 指定并行复制范围分区将使用的整数类型或日期/日期时间类型的源列(int、smallint、bigint、date、datetime2)的名称。 如果未指定,系统会自动检测表的索引或主键并将其用作分区列。当分区选项是 DynamicRange 时适用。 如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?DfDynamicRangePartitionCondition。 有关示例,请参阅从 Microsoft Fabric 仓库进行并行复制部分。 |
否 |
| partitionUpperBound | 分区范围拆分的分区列的最大值。 此值用于决定分区步幅,不用于筛选表中的行。 将对表或查询结果中的所有行进行分区和复制。 如果未指定,复制活动会自动检测该值。 当分区选项是 DynamicRange 时适用。 有关示例,请参阅从 Microsoft Fabric 仓库进行并行复制部分。 |
否 |
| partitionLowerBound | 分区范围拆分的分区列的最小值。 此值用于决定分区步幅,不用于筛选表中的行。 将对表或查询结果中的所有行进行分区和复制。 如果未指定,复制活动会自动检测该值。 当分区选项是 DynamicRange 时适用。 有关示例,请参阅从 Microsoft Fabric 仓库进行并行复制部分。 |
否 |
注意
在源中使用存储过程检索数据时,请注意,如果存储过程设计为当传入不同的参数值时返回不同的架构,则从 UI 导入架构或使用自动表创建将数据复制到 Microsoft Fabric 仓库时,可能会遇到故障或出现意外的结果。
示例:使用 SQL 查询
"activities":[
{
"name": "CopyFromMicrosoftFabricWarehouse",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Warehouse input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "WarehouseSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
示例:使用存储过程
"activities":[
{
"name": "CopyFromMicrosoftFabricWarehouse",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Warehouse input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "WarehouseSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
示例存储过程:
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
作为接收器类型的 Microsoft Fabric 仓库
Azure 数据工厂和 Synapse 管道支持使用 COPY 语句将数据加载到 Microsoft Fabric 仓库中。
要向 Microsoft Fabric 仓库复制数据,请将复制活动中的接收器类型设置为 WarehouseSink。 复制活动 sink 节支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| type | 复制活动接收器的“type”属性必须设置为“WarehouseSink”。 | 是 |
| allowCopyCommand | 指示是否使用 COPY 语句将数据加载到 Microsoft Fabric 仓库。 若要了解相关约束和详细信息,请参阅使用 COPY 语句将数据加载到 Microsoft Fabric 仓库部分。 允许的值为“True”。 |
是 |
| copyCommandSettings | allowCopyCommand 属性设置为 TRUE 时可以指定的一组属性。 |
否 |
| writeBatchTimeout | 此属性指定插入、更新插入和存储过程操作在超时之前完成的等待时间。 允许的值是指时间跨度。 例如,“00:30:00”表示 30 分钟。 如果未指定值,则超时默认为“00:30:00” |
否 |
| preCopyScript | 每次运行时,将数据写入到 Microsoft Fabric 仓库之前,指定复制活动要运行的 SQL 查询。 使用此属性清理预加载的数据。 | 否 |
| tableOption | 指定是否根据源架构自动创建接收器表(如果不存在)。 允许的值为:none(默认值)、autoCreate。 |
否 |
| disableMetricsCollection | 该服务收集指标,用于进行复制性能优化和提供建议,从而引入额外的主数据库访问权限。 如果你担心此行为,请指定 true 将其关闭。 |
否(默认值为 false) |
示例:Microsoft Fabric 仓库接收器
"activities":[
{
"name": "CopyToMicrosoftFabricWarehouse",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Microsoft Fabric Warehouse output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "WarehouseSink",
"allowCopyCommand": true,
"tableOption": "autoCreate",
"disableMetricsCollection": false
}
}
}
]
从 Microsoft Fabric 仓库并行复制
复制活动中的 Microsoft Fabric 仓库连接器提供内置的数据分区,用于并行复制数据。 可以在复制活动的“源”表中找到数据分区选项。
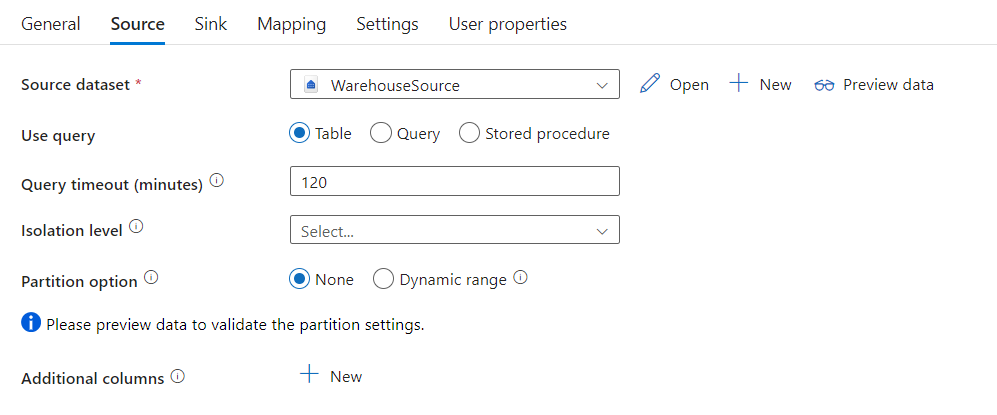
启用分区复制时,复制活动将对 Microsoft Fabric 仓库源运行并行查询,以按分区加载数据。 可通过复制活动中的 parallelCopies 设置控制并行度。 例如,如果将 parallelCopies 设置为 4,则该服务会根据指定的分区选项和设置并行生成并运行 4 个查询,每个查询从 Microsoft Fabric 仓库检索一部分数据。
建议同时启用并行复制和数据分区,尤其是从 Microsoft Fabric 仓库加载大量数据时。 下面是适用于不同方案的建议配置。 将数据复制到基于文件的数据存储中时,建议将数据作为多个文件写入文件夹(仅指定文件夹名称),在这种情况下,性能优于写入单个文件。
| 方案 | 建议的设置 |
|---|---|
| 从大型表中完全加载,同时使用整数或“日期/时间”列进行数据分区。 | 分区选项:动态范围分区。 分区列(可选):指定用于对数据进行分区的列。 如果未指定,将使用索引或主键列。 分区上限和分区下限(可选) :指定是否要确定分区步幅。 这不适用于筛选表中的行,表中的所有行都将进行分区和复制。 如果未指定,复制活动会自动检测这些值。 例如,如果分区列“ID”的值范围为 1 至 100,并且将此值的下限设置为 20、上限设置为 80,并行复制设置为 4,服务将按 4 个分区(分区的 ID 范围分别为 <=20、[21, 50]、[51, 80] 和 >=81)检索数据。 |
| 使用自定义查询加载大量数据,同时使用整数或“日期”/“日期/时间”列进行数据分区。 | 分区选项:动态范围分区。 查询: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>。分区列:指定用于对数据进行分区的列。 分区上限和分区下限(可选) :指定是否要确定分区步幅。 这不适用于筛选表中的行,查询结果中的所有行都将进行分区和复制。 如果未指定,复制活动会自动检测该值。 例如,如果分区列“ID”的值范围为 1 至 100,并且将此值的下限设置为 20、上限设置为 80,并行复制设置为 4,服务将按 4 个分区(分区的 ID 范围分别为 <=20、[21, 50]、[51, 80] 和 >=81)检索数据。 下面是针对不同场景的更多示例查询: 1.查询整个表: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2.使用列选择和附加的 where 子句筛选器从表中查询: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3.使用子查询进行查询: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4.在子查询中使用分区查询: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
使用分区选项加载数据的最佳做法:
- 选择独特的列作为分区列(如主键或唯一键),以避免数据倾斜。
- 如果使用 Azure Integration Runtime 复制数据,则可设置较大的“数据集成单元 (DIU)”(>4) 以利用更多计算资源。 检查此处适用的方案。
- “复制并行度”可控制分区数量,将此数字设置得太大有时会损害性能,建议将此数字设置按以下公式计算的值:(DIU 或自承载 IR 节点数)*(2 到 4)。
- 请注意:Microsoft Fabric 仓库一次最多可执行 32 个查询,将“复制并行度”设置得太大可能会导致仓库限制问题。
示例:使用动态范围分区进行查询
"source": {
"type": "WarehouseSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
使用 COPY 语句将数据加载到 Microsoft Fabric 仓库
使用 COPY 语句是一种简单且灵活的方法,以高吞吐量将数据加载到 Microsoft Fabric 仓库。 若要了解更多详细信息,请查看使用 COPY 语句大容量加载数据
- 如果源数据位于 Azure Blob 或 Azure Data Lake Storage Gen2 中,并且格式与 COPY 语句兼容,则可以使用复制活动直接调用 COPY 语句,使 Microsoft Fabric 仓库从源中拉取数据。 有关详细信息,请参阅 使用 COPY 语句直接复制 。
- 如果 COPY 语句最初不支持源数据存储和格式,请改用 使用 COPY 语句暂存复制 功能。 暂存复制功能也能提供更高的吞吐量。 它自动将数据转换为与 COPY 语句兼容的格式,将数据存储在 Azure Blob 存储中,然后调用 COPY 语句将数据加载到 Microsoft Fabric 仓库。
提示
在 Azure Integration Runtime 中使用 COPY 语句时,有效的数据集成单元 (DIU) 数始终为 2。 优化 DIU 不会影响性能。
使用 COPY 语句直接复制
Microsoft Fabric Warehouse COPY 语句直接支持 Azure Blob 和 Azure Data Lake Storage Gen2。 如果源数据满足本部分所述的条件,请使用 COPY 语句从源数据存储直接复制到 Microsoft Fabric 仓库。 否则,请使用使用 COPY 语句的暂存复制。 该服务会检查设置,如果不满足条件,复制活动运行将会失败。
源链接服务和格式使用以下类型和身份验证方法:
支持的源数据存储类型 支持的格式 支持的源身份验证类型 Azure Blob 带分隔符的文本 帐户密钥身份验证、共享访问签名身份验证 Parquet 帐户密钥身份验证、共享访问签名身份验证 Azure Data Lake Storage Gen2 带分隔符的文本
Parquet帐户密钥身份验证、共享访问签名身份验证 格式设置如下:
- 对于“Parquet”:
compression可以为“无压缩”、“Snappy”或GZip。 - 对于“带分隔符的文本”:
rowDelimiter显式设置为单字符或“\r\n”,不支持默认值。nullValue保留默认值或设置为空字符串 ("")。encodingName保留默认值或设置为 utf-8 或 utf-16。escapeChar必须与quoteChar相同,且不能为空。skipLineCount保留默认值或设置为 0。compression可以为“无压缩”或GZip。
- 对于“Parquet”:
如果源是文件夹,则必须将复制活动中的
recursive设置为 true,并且wildcardFilename需要为*或*.*。wildcardFolderPath、wildcardFilename(*或*.*除外)、modifiedDateTimeStart、modifiedDateTimeEnd、prefix、enablePartitionDiscovery和additionalColumns均未指定。
复制活动中的 allowCopyCommand 下支持以下 COPY 语句设置:
| 属性 | 描述 | 必需 |
|---|---|---|
| defaultValues | 为 Microsoft Fabric 仓库中的每个目标列指定默认值。 属性中的默认值将覆盖数据仓库中设置的 DEFAULT 约束,标识列不能有默认值。 | 否 |
| additionalOptions | 将直接在 COPY 语句的“With”子句中传递给 Microsoft Fabric 仓库 COPY 语句的其他选项。 根据需要将值括在引号中,以符合 COPY 语句要求。 | 否 |
"activities":[
{
"name": "CopyFromAzureBlobToMicrosoftFabricWarehouseViaCOPY",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "MicrosoftFabricWarehouseDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "WarehouseSink",
"allowCopyCommand": true,
"copyCommandSettings": {
"defaultValues": [
{
"columnName": "col_string",
"defaultValue": "DefaultStringValue"
}
],
"additionalOptions": {
"MAXERRORS": "10000",
"DATEFORMAT": "'ymd'"
}
}
},
"enableSkipIncompatibleRow": true
}
}
]
使用 COPY 语句的暂存复制
如果源数据不与 COPY 语句本机兼容,请通过临时暂存 Azure Blob 或 Azure Data Lake Storage Gen2(不能为 Azure 高级存储)来启用数据复制。 在这种情况下,该服务会自动转换数据,以满足 COPY 语句的数据格式要求。 然后,它调用 COPY 语句将数据加载到 Microsoft Fabric 仓库。 最后,它会从存储中清理临时数据。 若要详细了解如何通过暂存方式复制数据,请参阅暂存复制。
若要使用此功能,请创建 Azure Blob 存储链接服务或 Azure Data Lake Storage Gen2 链接服务,使用帐户密钥或系统托管标识身份验证,Azure 存储帐户用作临时存储。
重要
- 对暂存链接服务使用托管标识身份验证时,请分别了解 Azure Blob 和 Azure Data Lake Storage Gen2 所需的配置。
- 如果临时 Azure 存储配置了 VNet 服务终结点,则必须在存储帐户上启用“允许受信任的 Microsoft 服务”并使用托管标识身份验证,详见将 VNet 服务终结点与 Azure 存储配合使用的影响。
重要
如果你的暂存 Azure 存储配置了托管专用终结点并启用了存储防火墙,则必须使用托管标识身份验证并向 Synapse SQL Server 授予存储 Blob 数据读取器权限,以确保它可以在 COPY 语句加载期间访问暂存文件。
"activities":[
{
"name": "CopyFromSQLServerToMicrosoftFabricWarehouseViaCOPYstatement",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "MicrosoftFabricWarehouseDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "WarehouseSink",
"allowCopyCommand": true
},
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
映射数据流属性
转换映射数据流中的数据时,可以在 Microsoft Fabric Warehouse 的表中读取和写入。 有关详细信息,请参阅映射数据流中的源转换和接收器转换。
作为源的 Microsoft Fabric 仓库
特定于 Microsoft Fabric Warehouse 的设置将在源转换的“源选项”选项卡中提供。
| 名称 | 说明 | 必需 | 允许的值 | 数据流脚本属性 |
|---|---|---|---|---|
| Input | 选择是将源指向表(等效于 Select * from <表名>)、输入自定义 SQL 查询,还是从存储过程检索数据。 查询:如果在“输入”字段中选择“查询”,请为源输入 SQL 查询。 此设置会替代在数据集中选择的任何表。 此处不支持 Order By 子句,但你可以设置完整的 SELECT FROM 语句。 还可以使用用户定义的表函数。 select * from udfGetData() 是 SQL 中可返回表的 UDF。 此查询将生成可以在数据流中使用的源表。 使用查询也是减少要测试或查找的行的好方法。SQL 示例:Select * from MyTable where customerId > 1000 and customerId < 2000 |
是 | “表”、“查询”或“存储过程” | format: 'table' |
| 批次大小 | 输入批大小,以将大型数据分成多个读取操作。 在数据流中,会使用此设置来设置 Spark 分栏式缓存。 这是选项字段,如果留空,它将使用 Spark 默认值。 | 否 | 数字值 | batchSize: 1234 |
| 隔离级别 | 映射数据流中 SQL 源的默认设置为“读取未提交的内容”。 可以在此处将隔离级别更改为以下值之一:• 读取已提交的内容 • 读取未提交的内容 • 可重复读取 • 可序列化• 无(忽略隔离级别) | 是 | • 读取已提交的内容 • 读取未提交的内容 • 可重复读取 • 可序列化 • 无(忽略隔离级别) | isolationLevel |
注意
不支持通过暂存进行读取。 目前未提供对 Microsoft Fabric Warehouse 源的 CDC 支持。
作为接收器的 Microsoft Fabric Warehouse
特定于 Microsoft Fabric Warehouse 的设置将在接收器转换的“设置”选项卡中提供。
| 名称 | 说明 | 必需 | 允许的值 | 数据流脚本属性 |
|---|---|---|---|---|
| Update 方法 | 确定数据库目标上允许哪些操作。 默认设置为仅允许插入。 若要更新、更新插入或删除行,需要进行 alter-row 转换才能标记这些操作的行。 对于更新、更新插入和删除操作,必须设置一个或多个键列,以确定要更改的行。 | 是 | true 或 false | insertable deletable upsertable updateable |
| 表操作 | 确定是否在写入之前重新创建或移除目标表中的所有行。• 无:不会对表执行任何操作。 • 重新创建:将删除并重新创建表。 如果动态创建新表,则需要此项。• 截断:将移除目标表中的所有行。 | 否 | “无”、“重新创建”或“截断” | recreate: true truncate: true |
| 启用暂存 | 暂存存储是在执行数据流活动中配置的。 对存储链接服务使用托管标识身份验证时,请分别了解 Azure Blob 和 Azure Data Lake Storage Gen2 所需的配置。如果 Azure 存储配置了 VNet 服务终结点,则必须在使用托管标识身份验证时在存储帐户上启用“允许受信任的 Microsoft 服务”。有关详情,请参阅将 VNet 服务终结点与 Azure 存储配合使用的影响。 | 否 | true 或 false | staged: true |
| 批次大小 | 控制每个 Bucket 中写入的行数。 较大的批大小可提高压缩比并改进内存优化,但在缓存数据时可能会导致内存不足异常。 | 否 | 数字值 | batchSize: 1234 |
| 使用接收器架构 | 默认情况下,将在接收器架构下创建临时表作为过渡。 可以取消选中“使用接收器架构”选项,在“选择用户数据库架构”中指定架构名称,在该架构名称下,数据工厂将创建一个临时表来加载上游数据,并在完成后进行自动清理。 请确保已在数据库中创建表权限,并更改对架构的权限。 | 否 | true 或 false | stagingSchemaName |
| 预处理和后处理 SQL 脚本 | 输入将在数据写入接收器数据库之前(预处理)和之后(后处理)执行的多行 SQL 脚本 | 否 | SQL 脚本 | preSQLs:['set IDENTITY_INSERT mytable ON'] postSQLs:['set IDENTITY_INSERT mytable OFF'], |
行处理时出错
默认情况下,遇到第一个错误时,数据流运行会失败。 你可以选择“出错时继续”,确保即使各行存在错误,也可以完成数据流。 该服务提供了不同的选项来处理这些错误行。
事务提交:选择是在单个事务中写入数据,还是分批写入数据。 单个事务将提供更好的性能,且事务完成之前,其他人将看不到任何写入的数据。 批处理事务的性能较差,但适用于大型数据集。
输出已拒绝的数据:如果已启用,则可将错误行输出到 Azure Blob 存储或所选 Azure Data Lake Storage Gen2 帐户中的 csv 文件。 这会写入包含三个附加列的错误行:SQL 操作(例如插入或更新)、数据流错误代码,以及有关行的错误消息。
出错时报告成功:如果已启用,则即使发现了错误行,也会将数据流标记为成功。
注意
对于 Microsoft Fabric Warehouse 链接服务,服务主体支持的身份验证类型为“密钥”;不支持“证书”身份验证。
查找活动属性
若要了解有关属性的详细信息,请查看 Lookup 活动。
GetMetadata 活动属性
若要了解有关属性的详细信息,请查看 GetMetadata 活动
Microsoft Fabric 仓库的数据类型映射
当你从 Microsoft Fabric 仓库复制数据时,以下映射用于在内部从 Microsoft Fabric 仓库数据类型映射到服务临时数据类型。 若要了解复制活动如何将源架构和数据类型映射到接收器,请参阅架构和数据类型映射。
| Microsoft Fabric 仓库数据类型 | 数据工厂临时数据类型 |
|---|---|
| bigint | Int64 |
| binary | Byte[] |
| bit | Boolean |
| char | String, Char[] |
| date | DateTime |
| datetime2 | DateTime |
| Decimal | Decimal |
| FILESTREAM attribute (varbinary(max)) | Byte[] |
| Float | Double |
| int | Int32 |
| numeric | Decimal |
| real | Single |
| smallint | Int16 |
| time | TimeSpan |
| uniqueidentifier | Guid |
| varbinary | Byte[] |
| varchar | String, Char[] |
后续步骤
有关复制活动支持作为源和接收器的数据存储的列表,请参阅受支持的数据存储。