APPLIES TO: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
若要分析带分隔符的文本文件或以带分隔符的文本格式写入数据,请遵循此文章中的说明。
以下连接器支持带分隔符的文本格式:
- Amazon S3
- Amazon S3 兼容存储
- Azure Blob
- Azure Data Lake Storage Gen2
- Azure Files
- 文件系统
- FTP
- Google 云存储
- HDFS
- HTTP
- Oracle 云存储
- SFTP
数据集属性
有关可用于定义数据集的各部分和属性的完整列表,请参阅数据集一文。 本部分提供带分隔符的文本数据集支持的属性列表。
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 数据集的类型属性必须设置为 DelimitedText。 | 是 |
| 位置 | 文件的位置设置。 每个基于文件的连接器在 location 下都有其自己的位置类型和支持的属性。 |
是 |
| columnDelimiter | 用于分隔文件中的列的字符。 默认值为“逗号( ,)”。 当列分隔符定义为空字符串(意味着没有分隔符)时,整行将被视为单个列。目前,映射数据流仅支持将列分隔符用作空字符串,但不支持Copy activity。 |
否 |
| rowDelimiter | 对于Copy activity,用于分隔文件中的行的单个字符或“\r\n”。 默认值为以下任何一项:[“\r\n”、“\r”、“\n”](读取时);“\r\n”(写入时)。 “\r\n”仅在复制命令中受支持。 对于映射数据流,是用于分隔文件中的行的单个或两个字符。 默认值为以下任何一项:[“\r\n”、“\r”、“\n”](读取时);“\n”(写入时)。 当行分隔符设置为“无分隔符”(空字符串)时,列分隔符也必须设置为“无分隔符”(空字符串),这意味着将整个内容视为单个值。 目前,映射数据流仅支持行分隔符作为空字符串,但不支持Copy activity。 |
否 |
| quoteChar | 当列包含列分隔符时,用于括住列值的单个字符。 默认值为双引号 "。 将 quoteChar 定义为空字符串时,它表示不使用引号字符且不用引号括住列值,escapeChar 用于转义列分隔符和值本身。 |
否 |
| escapeChar | 用于转义括住值中的引号的单个字符。 默认值为反斜杠 \ 。 将 escapeChar 定义为空字符串时,quoteChar 也必须设置为空字符串。在这种情况下,应确保所有列值不包含分隔符。 |
否 |
| firstRowAsHeader | 指定是否要将第一行视为/设为包含列名称的标头行。 允许的值为 true 和 true(默认值)。 当“将第一行用作标题”为 false 时,请注意,UI 数据预览和查找活动输出会自动以 Prop_{n} 格式(从 0 开始)生成列名称,复制活动需要使用从源到接收器的显式映射,并且按序号(从 1 开始)定位各个列,映射数据流以 Column_{n} 格式(从 1 开始)的名称列出和定位各个列。 |
否 |
| nullValue | 指定 null 值的字符串表示形式。 默认值为空字符串。 |
否 |
| encodingName | 用于读取/写入测试文件的编码类型。 允许的值如下所示:“UTF-8”、“不带 BOM 的 UTF-8”、“UTF-16”、“UTF-16BE”、“UTF-32”、“UTF-32BE”、“US-ASCII”、“UTF-7”“BIG5”、“EUC-JP”、“EUC-KR”、“GB2312”、“GB18030”、“JOHAB”、“SHIFT-JIS”、“CP875”、“CP866”、“IBM00858”、“IBM037”、“IBM273”、“IBM437”、“IBM500”、“IBM737”、“IBM775”、“IBM850”、“IBM852”、“IBM855”、“IBM857”、“IBM860”、“IBM861”、“IBM863”、“IBM864”、“IBM865”、“IBM869”、“IBM870”、“IBM01140”、“IBM01141”、“IBM01142”、“IBM01143”、“IBM01144”、“IBM01145”、“IBM01146”、“IBM01147”、“IBM01148”、“IBM01149”、“ISO-2022-JP”、“ISO-2022-KR”、“ISO-8859-1”、“ISO-8859-2”、“ISO-8859-3”、“ISO-8859-4”、“ISO-8859-5”、“ISO-8859-6”、“ISO-8859-7”、“ISO-8859-8”、“ISO-8859-9”、“ISO-8859-13”、“ISO-8859-15”、“WINDOWS-874”、“WINDOWS-1250”、“WINDOWS-1251”、“WINDOWS-1252”、“WINDOWS-1253”、“WINDOWS-1254”、“WINDOWS-1255”、“WINDOWS-1256”、“WINDOWS-1257”、“WINDOWS-1258”。 注意,映射数据流不支持 UTF-7 编码。 请注意,映射数据流不支持使用字节顺序标记 (BOM) 进行 UTF-8 编码。 |
否 |
| compressionCodec | 用于读取/写入文本文件的压缩编解码器。 允许的值为 bzip2、gzip、deflate、ZipDeflate、TarGzip、Tar、snappy 或 lz4 。 默认设置是不压缩。 Note当前Copy activity不支持“snappy”和“lz4”,映射数据流不支持“ZipDeflate”、“TarGzip”和“Tar”。 注意,使用复制活动解压缩 ZipDeflateTarGzipTar 文件并将其写入基于文件的接收器数据存储时,默认情况下文件将提取到 / 文件夹,对复制活动源使用 / <path specified in dataset>/<folder named as source compressed file>/ 来控制是否以文件夹结构形式保留压缩文件名 。 |
否 |
| compressionLevel | 压缩率。 允许的值为 Optimal 或 Fastest。 - Fastest:尽快完成压缩操作,不过,无法以最佳方式压缩生成的文件。 - 最佳:以最佳方式完成压缩操作,不过,需要耗费更长的时间。 有关详细信息,请参阅 Compression Level(压缩级别)主题。 |
否 |
下面是Azure Blob Storage上带分隔符的文本数据集的示例:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Copy activity属性
有关可用于定义活动的各部分和属性的完整列表,请参阅管道一文。 本部分提供带分隔符的文本源和接收器支持的属性列表。
带分隔符的文本作为源
复制活动的 *source* 部分支持以下属性。
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 复制活动源的 type 属性必须设置为 DelimitedTextSource。 | 是 |
| formatSettings | 一组属性。 请参阅下面的“带分隔符的文本读取设置”表。 | 否 |
| storeSettings | 有关如何从数据存储读取数据的一组属性。 每个基于文件的连接器在 storeSettings 下都有其自己支持的读取设置。 |
否 |
下支持的formatSettings:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | formatSettings 的类型必须设置为 DelimitedTextReadSettings。 | 是 |
| skipLineCount | 指示从输入文件读取数据时要跳过的非空行数 。 如果同时指定了 skipLineCount 和 firstRowAsHeader,则先跳过行,然后从输入文件读取标头信息。 |
否 |
| compressionProperties | 一组属性,指示如何为给定的压缩编解码器解压缩数据。 | 否 |
| preserveZipFileNameAsFolder (在 compressionProperties->type 下为 ZipDeflateReadSettings) |
当输入数据集配置了 ZipDeflate 压缩时适用。 指示是否在复制过程中以文件夹结构形式保留源 zip 文件名。 - 如果设置为“true(默认)”,服务会将解压缩的文件写入 。 - 如果设置为“false”,服务会将解压缩的文件直接写入 。 请确保不同的源 zip 文件中没有重复的文件名,以避免产生冲突或出现意外行为。 |
否 |
| preserveCompressionFileNameAsFolder (在 compressionProperties->type 下为 TarGZipReadSettings 或 TarReadSettings) |
当输入数据集配置了 TarGzipTar 压缩时适用 。 指示是否在复制过程中以文件夹结构形式保留源压缩文件名。 - 如果设置为“true(默认)”,服务会将解压缩文件写入 。 - 如果设置为“false”,服务会将解压文件直接写入 。 请确保不同的源文件中没有重复的文件名,以避免产生冲突或出现意外行为。 |
否 |
"activities": [
{
"name": "CopyFromDelimitedText",
"type": "Copy",
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
},
"formatSettings": {
"type": "DelimitedTextReadSettings",
"skipLineCount": 3,
"compressionProperties": {
"type": "ZipDeflateReadSettings",
"preserveZipFileNameAsFolder": false
}
}
},
...
}
...
}
]
带分隔符的文本作为接收器
复制活动的 *sink* 部分支持以下属性。
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 复制活动源的 type 属性必须设置为 DelimitedTextSink。 | 是 |
| formatSettings | 一组属性。 请参阅下面的“带分隔符的文本写入设置”表。 | 否 |
| storeSettings | 有关如何将数据写入到数据存储的一组属性。 每个基于文件的连接器在 storeSettings 下都有其自身支持的写入设置。 |
否 |
下支持的formatSettings:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | formatSettings 的类型必须设置为 DelimitedTextWriteSettings。 | 是 |
| fileExtension | 用来为输出文件命名的扩展名,例如 .csv、.txt。 未在 DelimitedText 输出数据集中指定 fileName 时,必须指定该扩展名。 如果在输出数据集中配置了文件名,则它将其用作接收器文件名,并且将忽略文件扩展名设置。 |
未在输出数据集中指定文件名时为“是” |
| maxRowsPerFile | 在将数据写入到文件夹时,可选择写入多个文件,并指定每个文件的最大行数。 | 否 |
| fileNamePrefix | 配置 maxRowsPerFile 时适用。在将数据写入多个文件时,指定文件名前缀,生成的模式为 <fileNamePrefix>_00000.<fileExtension>。 如果未指定,将自动生成文件名前缀。 如果源是基于文件的存储或已启用分区选项的数据存储,则此属性不适用。 |
否 |
映射数据流属性
在映射数据流中,可以在以下数据存储中读取和写入带分隔符的文本格式:Azure Blob Storage、Azure Data Lake Storage Gen2 和 SFTP。
内联数据集
映射数据流支持将“内联数据集”作为定义源和接收器的选项。 内联分隔式数据集直接在源和接收器转换中定义,并且不会在定义的数据流外部共享。 该数据集对直接在数据流中参数化数据集属性非常有用,并且可以从共享 ADF 数据集的性能改进中获益。
读取大量源文件夹和文件时,可以通过在“投影 | 架构”选项对话框中设置选项“用户投影架构”来提升数据流文件发现的性能。 此选项会关闭 ADF 的默认架构自动发现,并将极大地提升文件发现的性能。 在设置此选项前,请务必导入投影,以便 ADF 具有用于投影的现有架构。 此选项不适用于架构偏差。
源属性
下表列出了带分隔符的文本源支持的属性。 你可以在“源选项”选项卡中编辑这些属性。
| 名称 | 描述 | 必需 | 允许的值 | 数据流脚本属性 |
|---|---|---|---|---|
| 通配符路径 | 将处理与通配符路径匹配的所有文件。 重写数据集中设置的文件夹和文件路径。 | 否 | String[] | wildcardPaths |
| 分区根路径 | 对于已分区的文件数据,可以输入分区根路径,以便将已分区的文件夹读取为列 | 否 | 字符串 | partitionRootPath |
| 文件列表 | 源是否指向某个列出待处理文件的文本文件 | 否 |
true 或 false |
fileList |
| 多行行 | 源文件是否包含跨多个行的行。 多行值必须用引号引起来。 | 否 true 或 false |
multiLineRow | |
| 用于存储文件名的列 | 使用源文件名称和路径创建新列 | 否 | 字符串 | rowUrlColumn |
| 完成后 | 在处理后删除或移动文件。 文件路径从容器根开始 | 否 | 删除:true 或 false Move: ['<from>', '<to>'] |
purgeFiles moveFiles |
| 按上次修改时间筛选 | 选择根据上次更改时间筛选文件 | 否 | 时间戳 | modifiedAfter modifiedBefore |
| 允许找不到文件 | 如果为 true,则找不到文件时不会引发错误 | 否 |
true 或 false |
ignoreNoFilesFound |
| 最大列数 | 默认值为 20480。 当列号超出 20480 时自定义此值 | 否 | Integer | maxColumns |
注意
文件列表的数据流源支持仅限文件中的 1024 项。 若要包含更多文件,请在文件列表中使用通配符。
源示例
下图是映射数据流中带分隔符的文本源配置的示例。
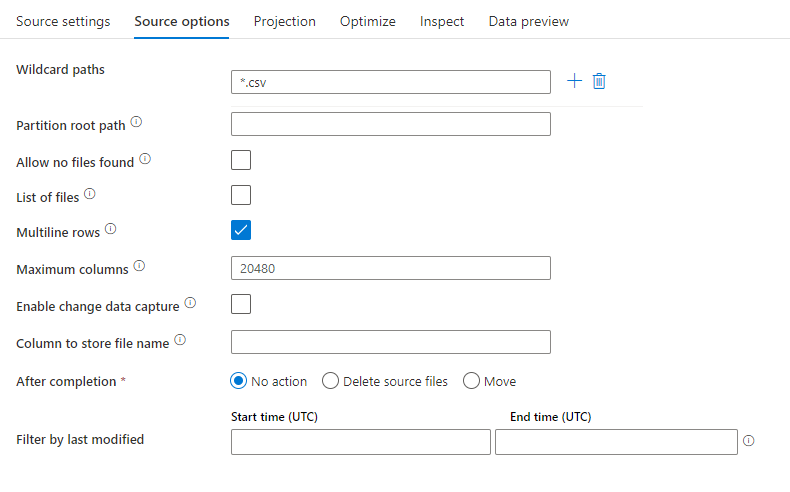
关联的数据流脚本为:
source(
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
multiLineRow: true,
wildcardPaths:['*.csv']) ~> CSVSource
注意
数据流源支持 Hadoop 文件系统支持的一组有限的 Linux 通配
接收器属性
下表列出了带分隔符的文本接收器支持的属性。 可以在“设置”选项卡中编辑这些属性。
| 名称 | 描述 | 必需 | 允许的值 | 数据流脚本属性 |
|---|---|---|---|---|
| 清除文件夹 | 如果在写入前目标文件夹已被清除 | 否 |
true 或 false |
截断 |
| 文件名选项 | 写入的数据的命名格式。 默认情况下,每个分区有一个 part-#####-tid-<guid> 格式的文件 |
否 | 模式:字符串 每分区:String[] 将文件命名为列数据:字符串 输出到单个文件: ['<fileName>'] 将文件夹命名为列数据:字符串 |
filePattern partitionFileNames rowUrlColumn partitionFileNames rowFolderUrlColumn |
| 全部引用 | 将所有值括在引号中 | 否 |
true 或 false |
quoteAll |
| 标头 | 向输出文件添加客户标头 | 否 | [<string array>] |
标头 |
接收器示例
下图是映射数据流中带分隔符的文本接收器配置的示例。
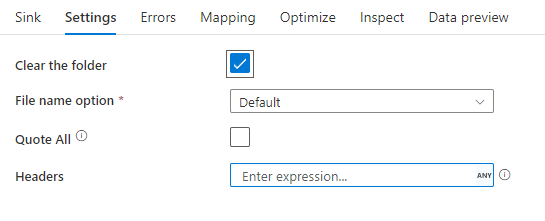
关联的数据流脚本为:
CSVSource sink(allowSchemaDrift: true,
validateSchema: false,
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CSVSink
相关连接器和格式
下面是与带分隔符的文本格式相关的一些常见连接器和格式: