适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
数据流在 Azure 数据工厂管道和 Azure Synapse Analytics 管道中都可用。 本文适用于映射数据流。 如果你不熟悉转换,请参阅介绍性文章: 使用映射数据流转换数据。
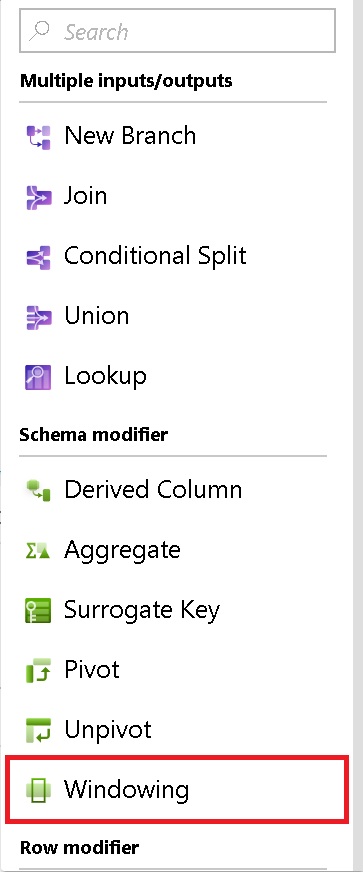
在窗口转换中,你定义数据流中基于窗口的列的聚合。 在表达式生成器中,可以定义基于数据或时间窗口(SQL OVER 子句)的不同类型的聚合,如 LEAD、LAG、NTILE、CUMEDIST 和 RANK。 输出中会生成包含这些聚合的新字段。 还可以包含可选的分组字段。
结束
为您的窗口变换设置列数据分区。 SQL 等效项是 SQL 中 Over 子句中的 Partition By。 如果你希望创建用于分区的计算或表达式,可以将鼠标悬停在列名上并选择“计算列”。
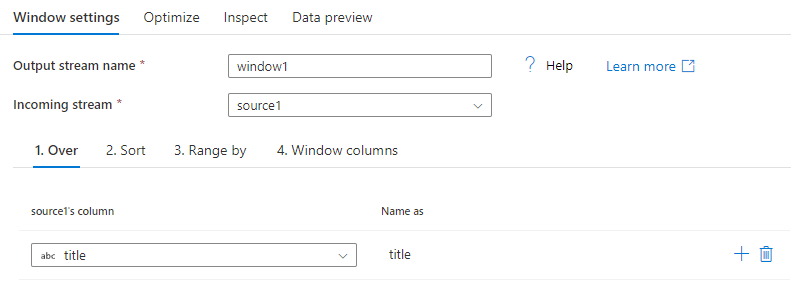
排序
Over 子句的另一部分是进行Order By的设置。 此子句设置数据排序顺序。 还可以在此列字段中为计算值创建表达式以进行排序。
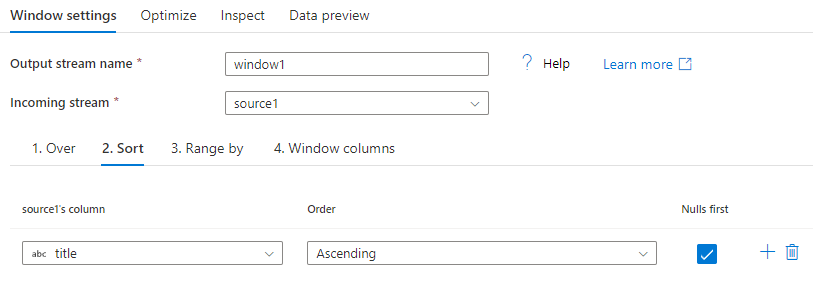
按范围设置
接下来,将窗口框架设置为“无界”或“有界”。 若要设置无界窗框,请将滑块两端设置为“无界”。 如果选择在无界与当前行之间的设置,那么必须设置偏移量的起始值和结束值。 这两个值都是正整数。 可以使用数据中的相对数字或值。
窗口滑块有两个要设置的值:当前行之前的值和当前行之后的值。 开始位置和结束位置之间的距离与滑块上的两个选择器匹配。
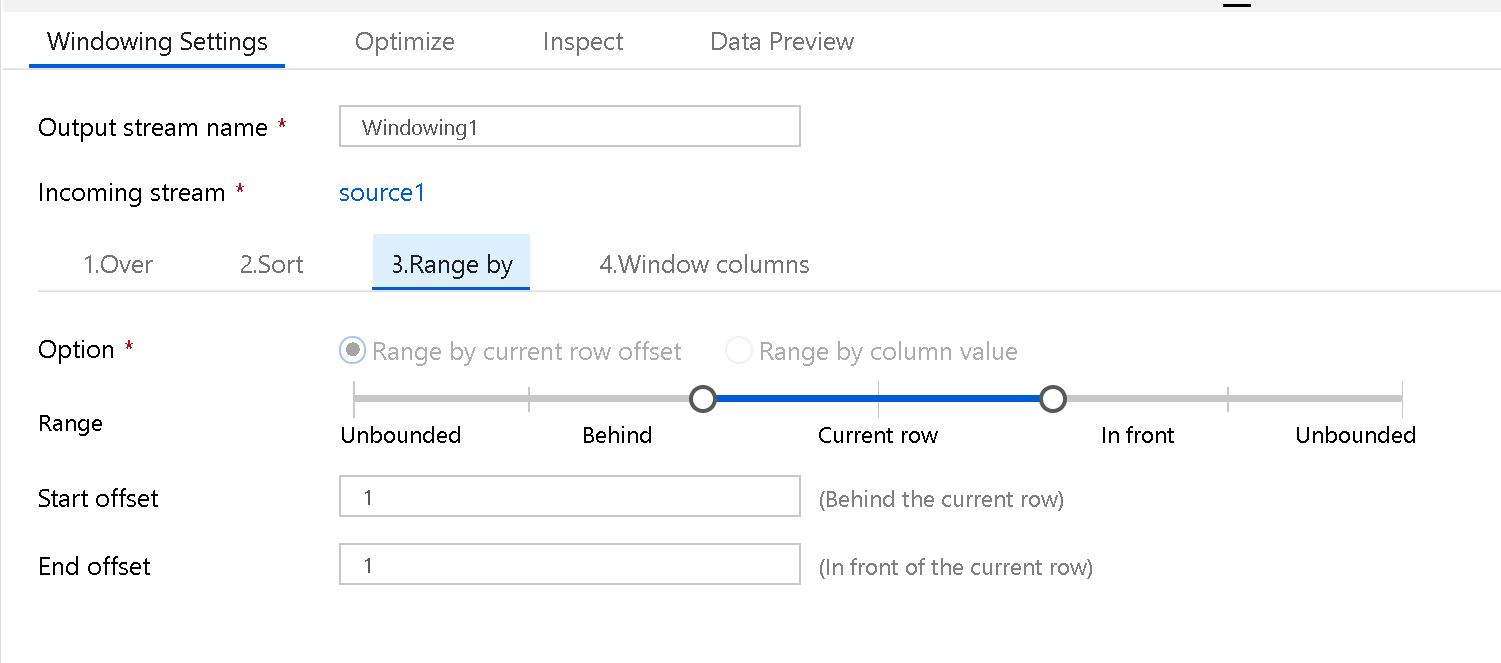
窗格列
最后,使用表达式生成器定义你希望与数据窗口一起使用的聚合,例如 RANK、COUNT、MIN、MAX、DENSE RANK、LEAD 和 LAG 等。
映射数据流中的数据转换表达式列出了可通过表达式生成器采用数据流表达式语言使用的聚合和分析函数的完整列表。
相关内容
如果您正在寻找简单的分组聚合,请使用聚合转换