适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
数据流可在Azure Data Factory管道和Azure Synapse Analytics管道中使用。 本文适用于映射数据流。 如果你不熟悉转换,请参阅介绍性文章: 使用映射数据流转换数据。
使用“更改行”转化来设置针对行的插入、删除、更新和合并策略。 可以将一对多条件添加为表达式。 应按优先级顺序指定这些条件,因为每一行都将用与第一个匹配的表达式对应的策略进行标记。 其中的每个条件都可能会导致对行执行插入、更新、删除或更新插入操作。 “更改行”可能会产生对数据库的 DDL 和 DML 操作。
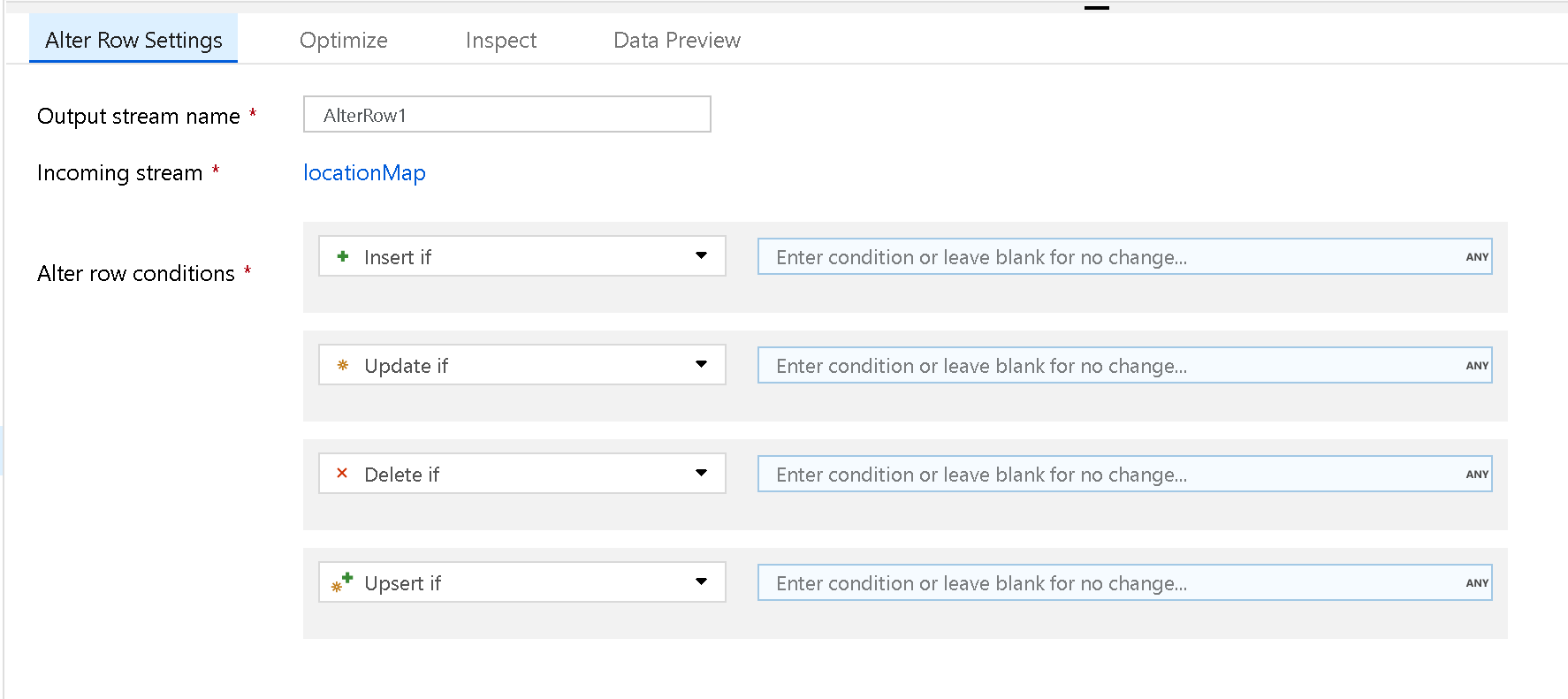
更改行转换仅在数据流中的数据库、REST 或 Azure Cosmos DB 汇聚点上运行。 在调试会话期间,分配给行的操作(插入、更新、删除、更新插入)不会发生。 若要在数据库表上实施更改行策略,请在管道中运行“执行 Data Flow 活动”。
注意
对于使用本机 CDC 源(如 SQL Server 或 SAP)的变更数据捕获数据流,不需要更改行转换。 在这些情况下,ADF 将自动检测行标记,因此不需要更改行策略。
指定一个默认行策略
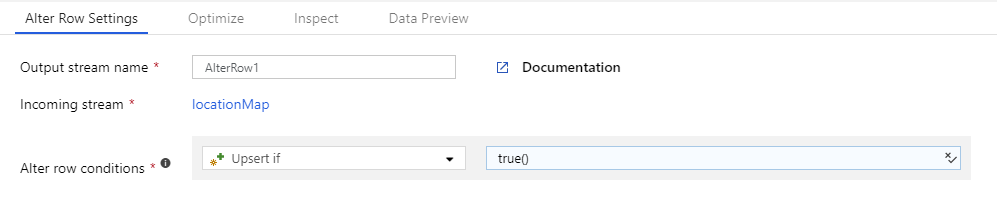
创建一个“更改行”转换,并指定一个条件为 true() 的行策略。 与前面定义的任何表达式都不匹配的每个行都将标记为执行指定的行策略。 默认情况下,与任何条件表达式都不匹配的每行都会被标记以执行 Insert。
注意
若要为所有行标记一个策略,可以为该策略创建一个条件,并将条件指定为 true()。
在数据预览中查看策略
使用调试模式在数据预览窗格中查看“更改行”策略的结果。 “更改行转换”数据预览不会对目标执行 DDL 或 DML 操作。
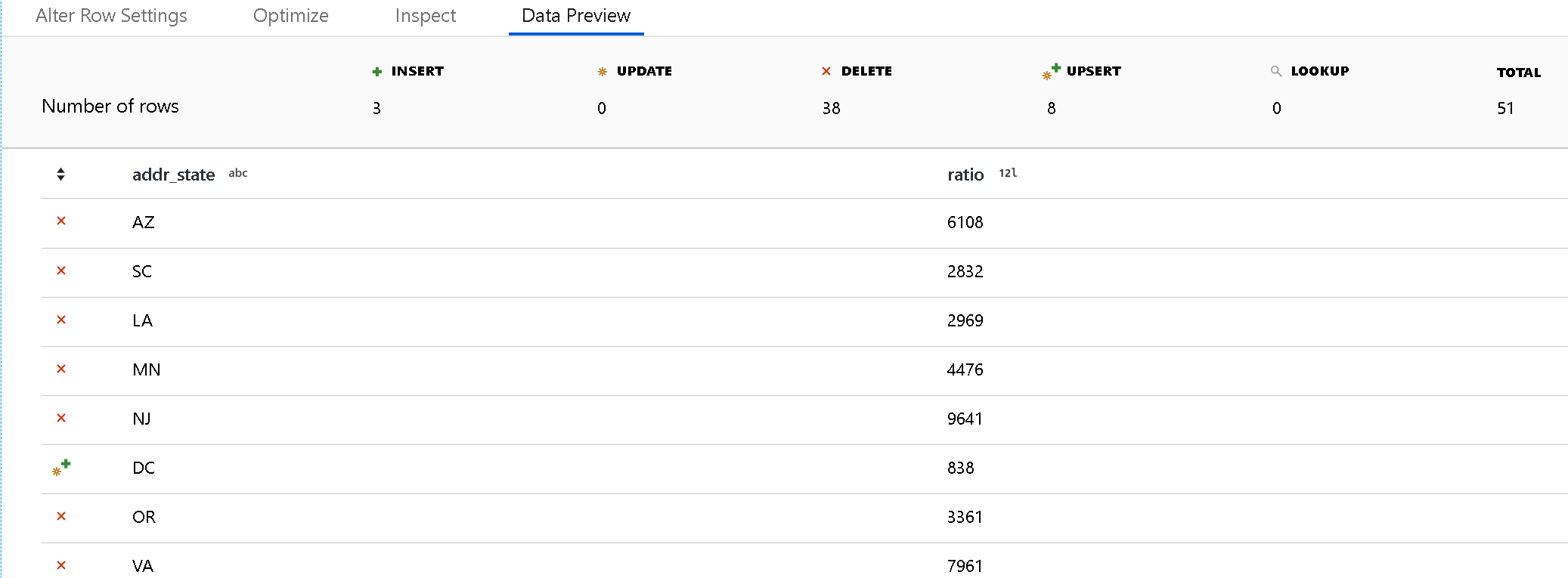
每个“更改行”策略的图标指示会发生插入、更新、更新插入还是删除操作。 在预览中,顶部标题会显示每个策略所影响的行数。
在接收器中允许“修改行策略”
要使更改行策略正常工作,数据流必须写入数据库或 Azure Cosmos DB 汇集器。 在接收器的“设置”选项卡中,启用允许在该接收器中使用的行更改策略。
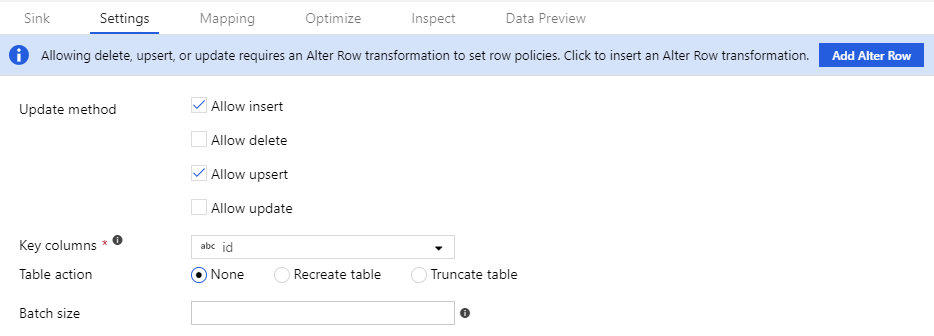
默认行为是仅允许插入。 若要允许更新、更新插入或删除,请选中接收器中与该条件对应的框。 如果启用更新、更新插入或删除操作,则必须指定接收器中与之匹配的键列。
注意
如果插入、更新或合并操作修改了汇聚中目标表的架构,则数据流会失败。 若要修改数据库中的目标架构,请选择“重新创建表”作为表操作。 这将删除表并使用新的架构定义重新创建表。
下沉转换需要单个键或一系列键才能在目标数据库中对行进行唯一标识。 对于 SQL 接收器,在接收器设置选项卡中设置密钥。对于 Azure Cosmos DB,请在设置中设置分区键,并在接收器映射中设置 Azure Cosmos DB 系统字段 “ID”。 对于 Azure Cosmos DB,必须在更新、插入或更新以及删除操作中包括系统列“ID”。
在Azure SQL Database和Azure Synapse中进行合并和更新插入操作
数据流支持使用 upsert 选项针对Azure SQL Database和Azure Synapse数据库池(数据仓库)进行合并。
但是,你可能会遇到目标数据库架构使用了键列的标识属性的情况。 此服务要求你标识用于匹配行值以进行更新和插入更新操作的键。 但是,如果目标列设置了标识属性,而你使用的是更新插入策略,则目标数据库不允许写入到列。 尝试对分布式表的分布列进行插入更新时,您可能也会遇到错误。
下面是解决该问题的方法:
前往“Sink 转换设置”并设置为“跳过写入关键列”。 这将指示此服务不要写入你选择用作映射键值的列。
如果该键列不是导致标识列问题的列,则可以使用“Sink 转换”中的预处理 SQL 选项:
SET IDENTITY_INSERT tbl_content ON。 然后,通过以下后处理 SQL 属性将其关闭:SET IDENTITY_INSERT tbl_content OFF。对于标识列情况和分布列情况,可以通过“条件拆分”转换,将逻辑从使用 Upsert 切换为使用单独的更新条件和单独的插入条件。 这样即可将更新路径上的映射设置为忽略键列映射。
数据流脚本
语法
<incomingStream>
alterRow(
insertIf(<condition>?),
updateIf(<condition>?),
deleteIf(<condition>?),
upsertIf(<condition>?),
) ~> <alterRowTransformationName>
示例
下面的示例是一个名为 CleanData 的“行更改转换”,它接收传入流 SpecifyUpsertConditions 并创建三个行更改条件。 在上一转换中计算了名为 alterRowCondition 的列,目的是确定是否在数据库中插入、更新或删除行。 如果列的值包含与“更改行”规则匹配的字符串值,则会为其分配该策略。
在 UI 中,此转换如下图所示:
此转换的数据流脚本位于下面的代码片段中:
SpecifyUpsertConditions alterRow(insertIf(alterRowCondition == 'insert'),
updateIf(alterRowCondition == 'update'),
deleteIf(alterRowCondition == 'delete')) ~> AlterRow
相关内容
完成“更改行”转换后,即可将数据加载到目标数据存储中。