适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
数据流在 Azure 数据工厂管道和 Azure Synapse Analytics 管道中都可用。 本文适用于映射数据流。 如果你不熟悉转换,请参阅介绍性文章: 使用映射数据流转换数据。
使用代理键转换向每行数据添加递增的键值。 在星型架构分析数据模型中设计维度表时,这非常有用。 在星型架构中,维度表中的每个成员都需要唯一键,该键需要是一个非业务键。
配置
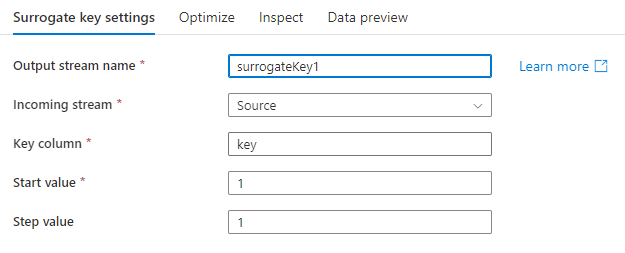
关键列:生成的代理键列的名称。
起始值: 生成的最小键值。
从现有源增加键
若要从源中存在的值启动序列,我们建议使用缓存接收器来保存该值,并使用派生列转换将这两个值一起添加。 使用缓存查找功能来获取输出,并将其附加到生成的键中。 有关详细信息,请了解缓存接收器和缓存查找。
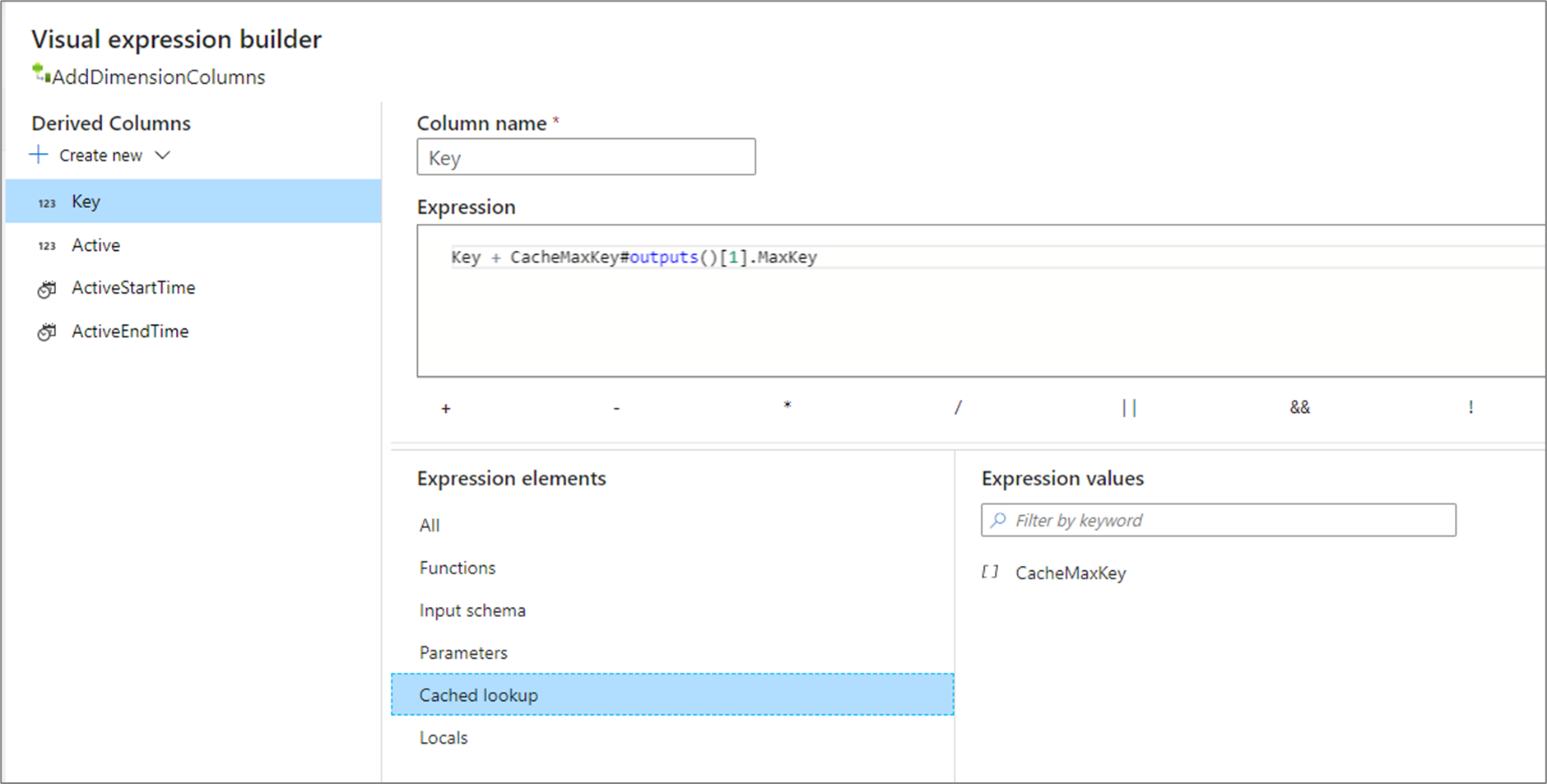
从当前最大值开始增加
根据源数据的位置,可以使用两种技术将键值初始化为先前的最大值。
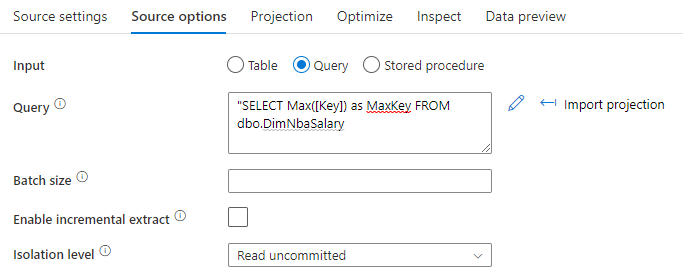
数据库源
使用 SQL 查询选项从源中选择 MAX()。 例如,Select MAX(<surrogateKeyName>) as maxval from <sourceTable>。
文件源
如果之前的最大值位于文件中,请使用聚合转换中的 max() 函数获取之前的最大值:
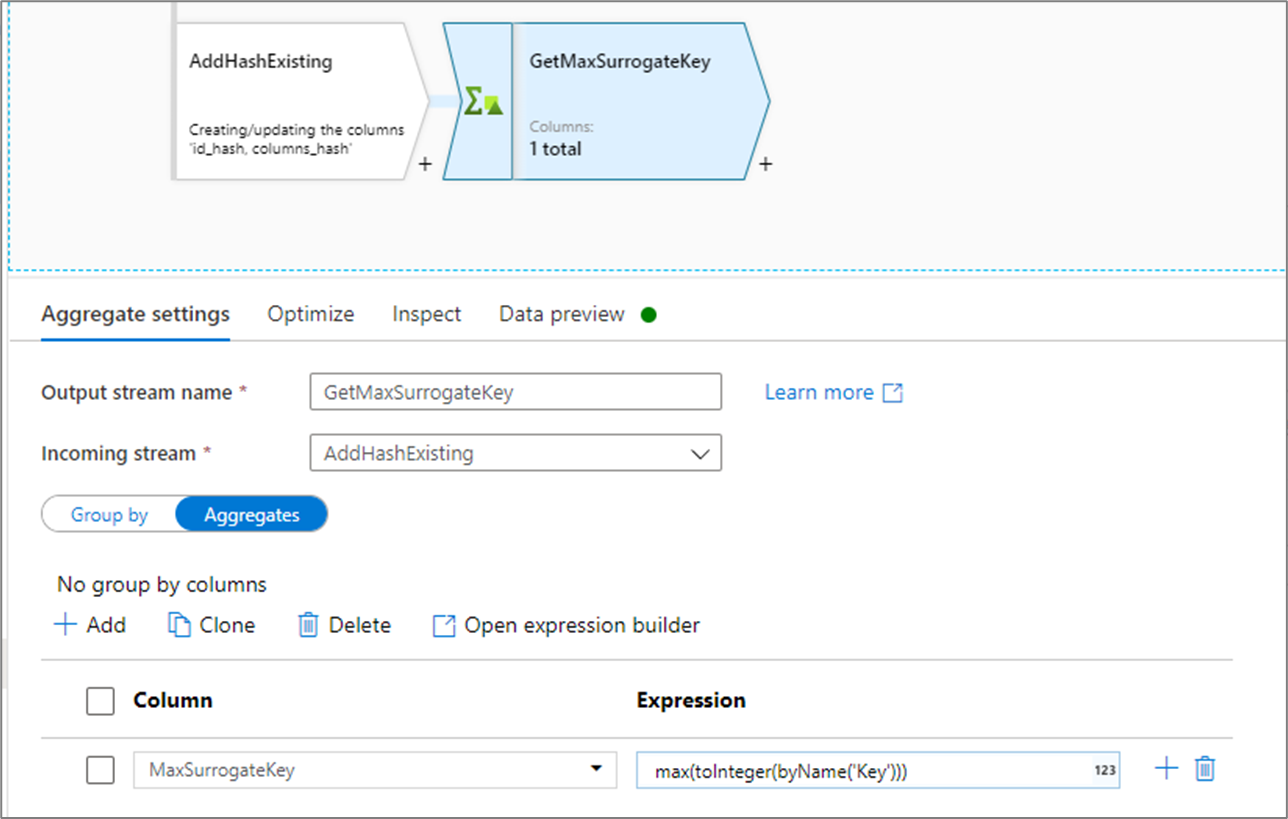
在这两种情况下,你都需要写入缓存输出端并查找值。
数据流脚本
语法
<incomingStream>
keyGenerate(
output(<surrogateColumnName> as long),
startAt: <number>L
) ~> <surrogateKeyTransformationName>
示例
以上代理键配置的数据流脚本位于下面的代码片段中。
AggregateDayStats
keyGenerate(
output(key as long),
startAt: 1L
) ~> SurrogateKey1