重要
此连接器可用于 Microsoft Fabric 中的实时智能。 使用本文中的说明时,请注意以下例外情况:
- 如果需要,请按照创建 KQL 数据库中的说明创建数据库。
- 如果需要,请按照创建空表中的说明创建表。
- 使用复制 URI 中的说明获取查询或引入 URI。
- 在 KQL 查询集中运行查询。
Azure 数据资源管理器是一个快速、完全托管的数据分析服务。 它可以实时分析从应用程序、网站和 IoT 设备等许多源流式传输的大量数据。 使用 Azure 数据资源管理器,可以迭代方式浏览数据,识别模式和异常以改进产品、增强客户体验、监视设备,以及提升操作性能。 它可以帮助你探讨新的问题,并在短时间内获得解答。
Azure 数据工厂是一个完全托管的基于云的数据集成服务。 可以使用它在 Azure 数据资源管理器数据库中填充现有系统中的数据。 它可以帮助你节省生成分析解决方案所花费的时间。
将数据载入 Azure 数据资源管理器时,数据工厂可提供以下优势:
- 轻松设置:使用直观的五步骤向导,无需编写脚本。
- 丰富的数据存储支持:对一组丰富的本地和基于云的数据存储的内置支持。 有关详细列表,请参阅表支持的数据存储。
- 安全且合规:通过 HTTPS 或 Azure ExpressRoute 传输数据。 存在全局服务可确保数据永远不会离开地理边界。
- 高性能:向 Azure 数据资源管理器载入数据的速度高达 1 GBps。 有关详细信息,请参阅复制活动性能。
在本文中,你将使用数据工厂复制数据工具,将数据从 Amazon 简单存储服务 (S3) 载入 Azure 数据资源管理器。 可以遵循类似的步骤,从下述其他数据存储复制数据:
先决条件
创建数据工厂
登录到 Azure 门户。
在左窗格中,选择“创建资源”“Analytics”>“数据工厂”。

在“新建数据工厂”窗格中,提供下表中的字段值:
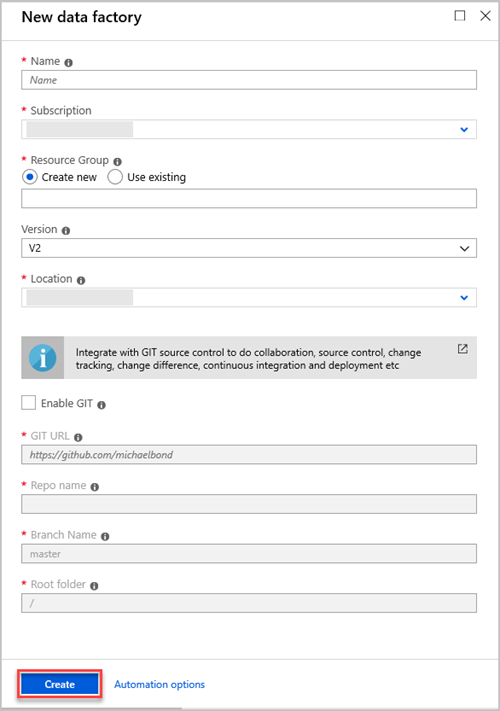
设置 要输入的值 名称 在框中输入数据工厂的全局唯一名称。 如果收到错误数据工厂名称“LoadADXDemo”不可用,请输入不同的数据工厂名称。 有关数据工厂项目的命名规则,请参阅数据工厂命名规则。 订阅 在下拉列表中,选择要在其中创建数据工厂的 Azure 订阅。 资源组 选择“新建”,然后输入新资源组的名称。 如果已有一个资源组,请选择“使用现有项”。 版本 在下拉列表中,选择 V2。 位置 在下拉列表中,选择数据工厂的位置。 该列表仅显示支持的位置。 数据工厂使用的数据存储可位于其他位置或区域中。 选择“创建” 。
若要监视创建过程,请在工具栏上选择“通知”。 创建数据工厂后,将其选中。
此时会打开“数据工厂”窗格。
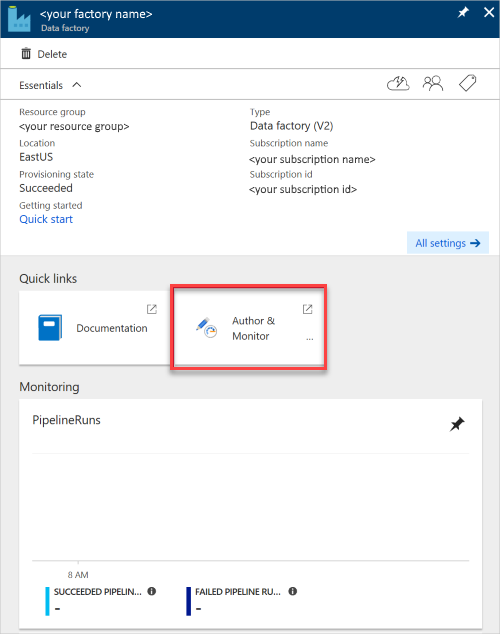
若要在单独的窗格中打开应用程序,请选择“创作和监视”磁贴。
将数据载入 Azure 数据资源管理器
可将许多类型的数据存储中的数据载入 Azure 数据资源管理器。 本文介绍如何从 Amazon S3 加载数据。
可通过以下任一方式加载数据:
- 在 Azure 数据工厂用户界面的左窗格中,选择“创建者”图标。 使用 Azure 数据工厂 UI 创建数据工厂的“创建数据工厂”部分对此进行了说明。
- 使用 Azure 数据工厂复制数据工具,如使用复制数据工具复制数据中所述。
从 Amazon S3(源)复制数据
在“开始使用”窗格中,选择“复制数据”打开复制数据工具。
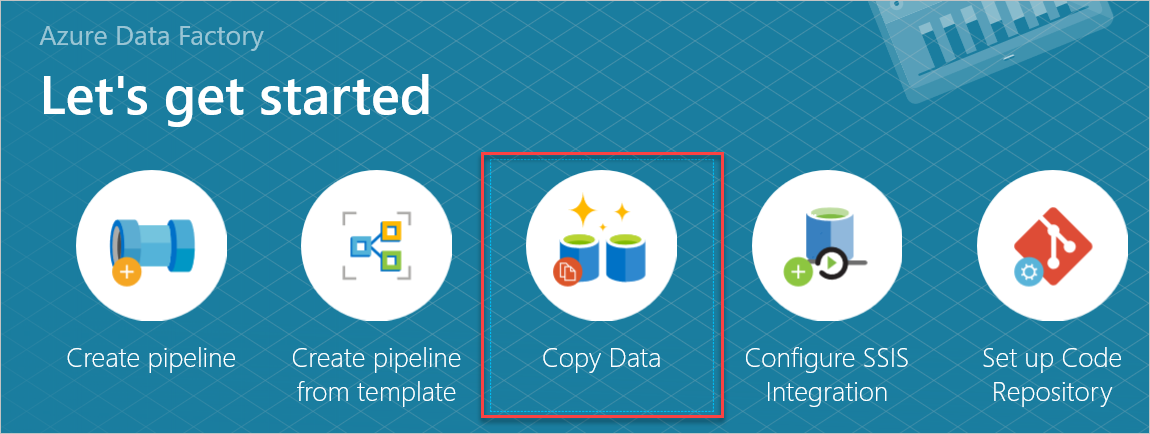
在“属性”窗格中的“任务名称”框内输入名称,然后选择“下一步”。
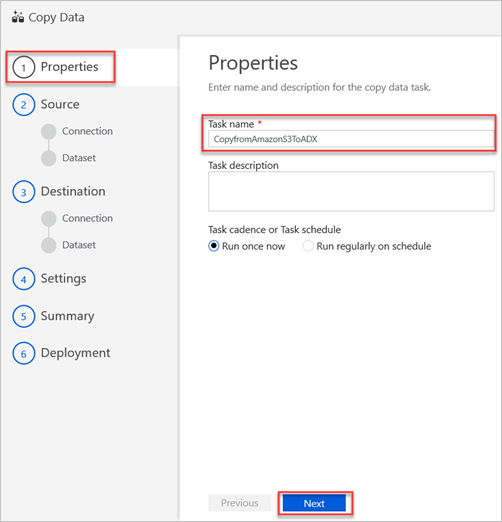
在“源数据存储”窗格中,选择“创建新连接”。
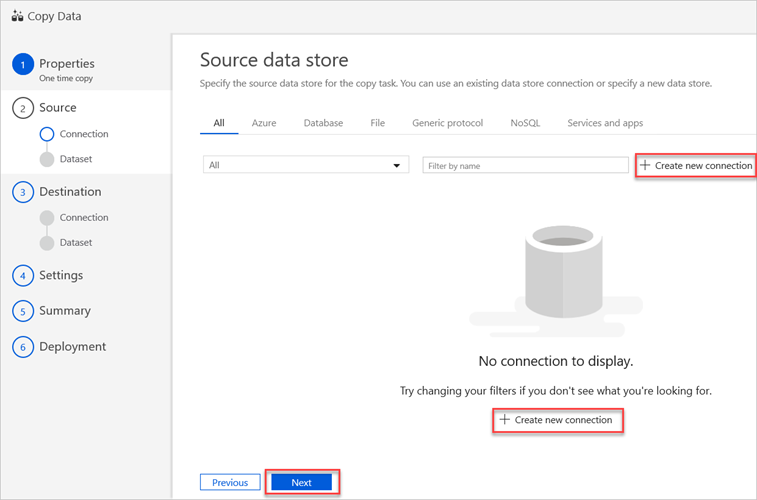
依次选择“Amazon S3”、“继续”。
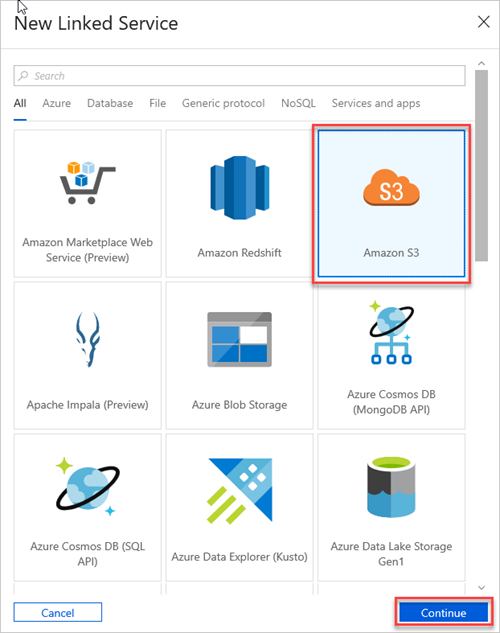
在“新建链接服务(Amazon S3)”窗格中执行以下操作:
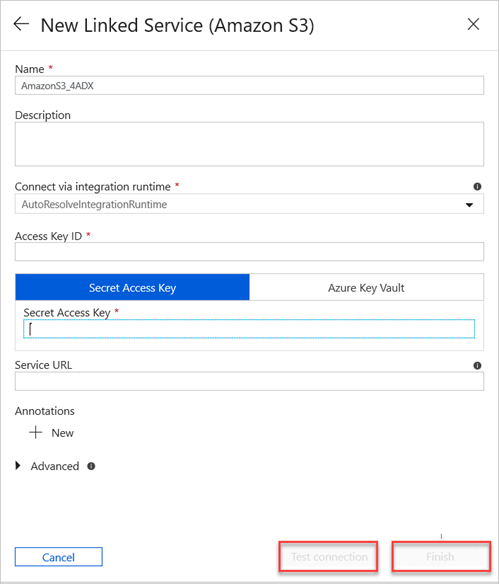
a。 在“名称”框中,输入新链接服务的名称。
b. 在“通过集成运行时进行连接”下拉列表中选择值。
选项c. 在“访问密钥 ID”框中输入值。
注意
若要在 Amazon S3 中查找访问密钥,请在导航栏上选择自己的 Amazon 用户名,然后选择“我的安全凭据”。
d。 在“机密访问密钥”中输入值。
e。 若要测试创建的链接服务连接,请选择“测试连接”。
f。 选择“完成”。
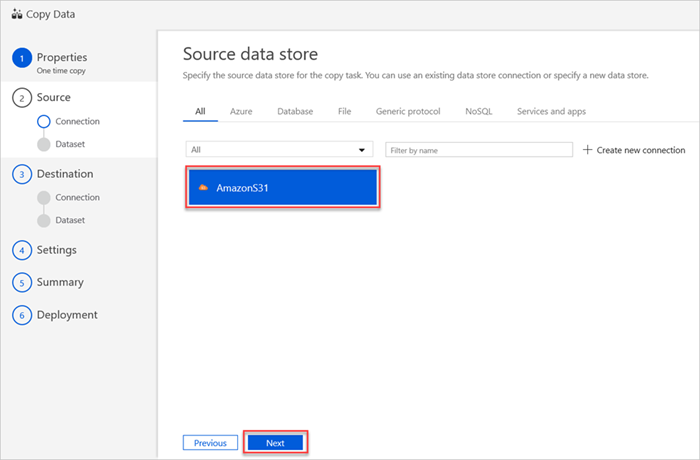
“源数据存储”窗格中会显示新的 AmazonS31 连接。
选择“下一步”。
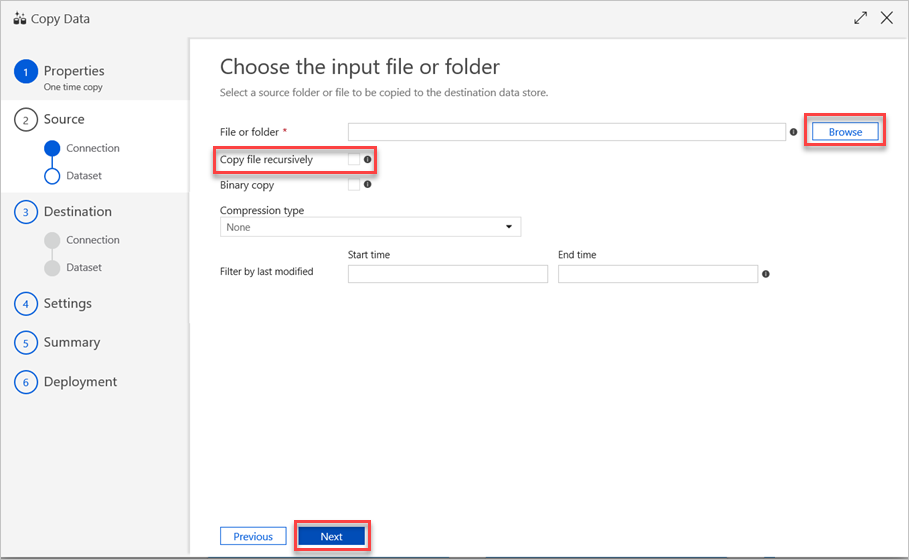
在“选择输入文件或文件夹”窗格中执行以下步骤:
a。 浏览到要复制的文件或文件夹并将其选中。
b. 选择所需的复制行为。 请确保未选中“二进制副本”复选框。
选项c. 选择“下一步”。
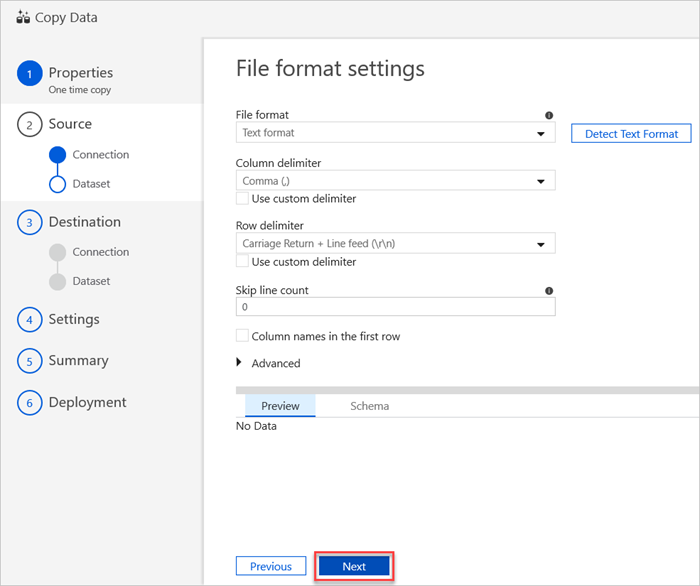
在“文件格式设置”窗格中选择文件的相关设置。 然后选择“下一步”。
将数据复制到 Azure 数据资源管理器(目标)
现已创建新的 Azure 数据资源管理器链接服务,用于将数据复制到本部分指定的 Azure 数据资源管理器目标表(接收器)。
注意
使用 Azure 数据工厂命令活动运行 Azure 数据资源管理器管理命令,并使用任何“从查询引入”命令(例如 .set-or-replace)。
创建 Azure 数据资源管理器链接服务
若要创建 Azure 数据资源管理器链接服务,请执行以下步骤:
若要使用现有的数据存储连接或指定新的数据存储,请在“目标数据存储”窗格中选择“创建新连接”。
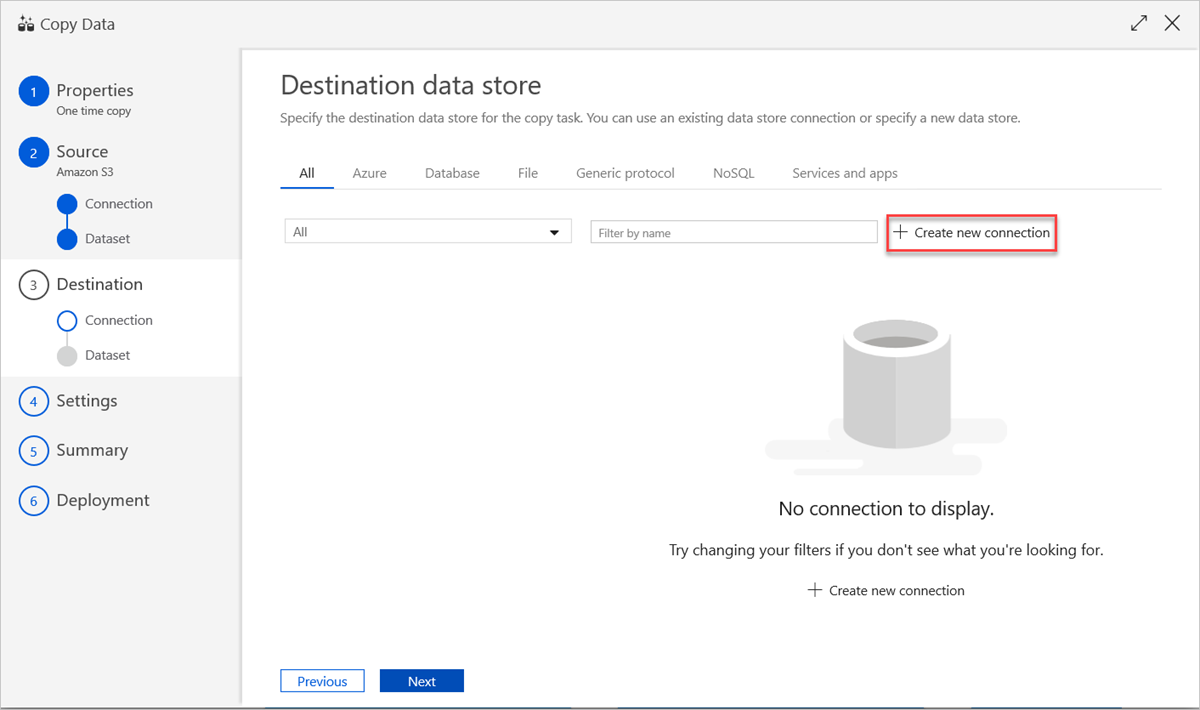
在“新建链接服务”窗格中选择“Azure 数据资源管理器”,然后选择“继续”。

在“新建链接服务(Azure 数据资源管理器)”窗格中执行以下步骤:
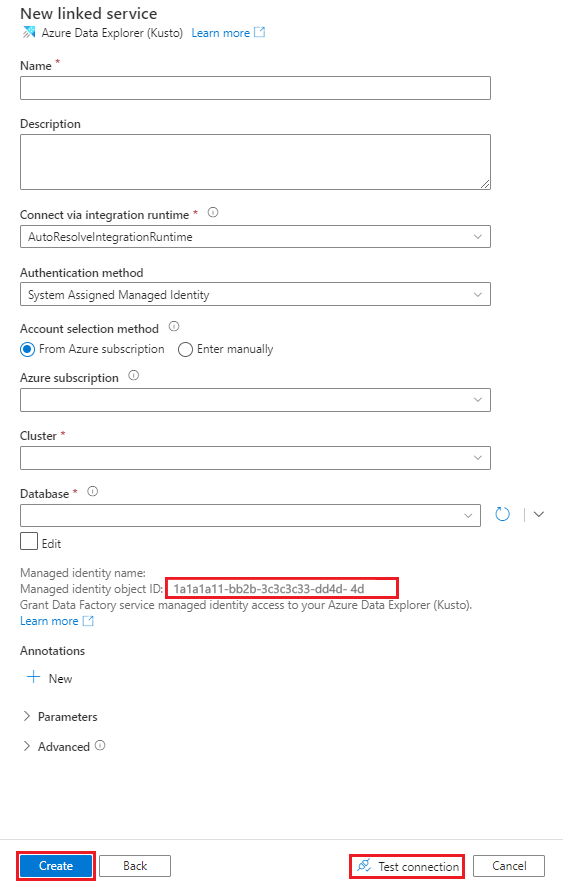
在“名称”框中,输入 Azure 数据资源管理器链接服务的名称。
在“身份验证方法”下,选择系统分配的托管标识或服务主体。
要使用托管标识进行身份验证,请使用托管标识名称或托管身份对象 ID 授予托管标识访问数据库的权限。
使用服务主体进行身份验证:
- 在“租户”框中输入租户名称。
- 在“服务主体 ID”框中输入服务主体 ID。
- 选择“服务主体密钥”,然后在“服务主体密钥”框中输入密钥的值。
注意
- Azure 数据工厂使用服务主体来访问 Azure 数据资源管理器服务。
- 要将权限分配给托管标识或服务主体,请参阅管理权限。
- 不要使用 Azure Key Vault 方法或用户分配的托管标识。
在“帐户选择方法”下,选择以下选项之一:
选择“从 Azure 订阅”,然后在下拉列表中,选择你的 Azure 订阅和群集。
选择“手动输入”,然后输入你的终结点。
在 “数据库 ”下拉列表中,选择数据库名称。 或者,选中“编辑”复选框,然后输入数据库名称。
若要测试创建的链接服务连接,请选择“测试连接”。 如果可以连接到该链接服务,该窗格将显示绿色的勾选标记和“连接成功”消息。
选择“创建”以完成链接服务的创建。
配置 Azure 数据资源管理器数据连接
创建链接服务连接后,“目标数据存储”窗格将会打开,创建的连接可供使用。 若要配置连接,请执行以下步骤:
选择“下一步”。
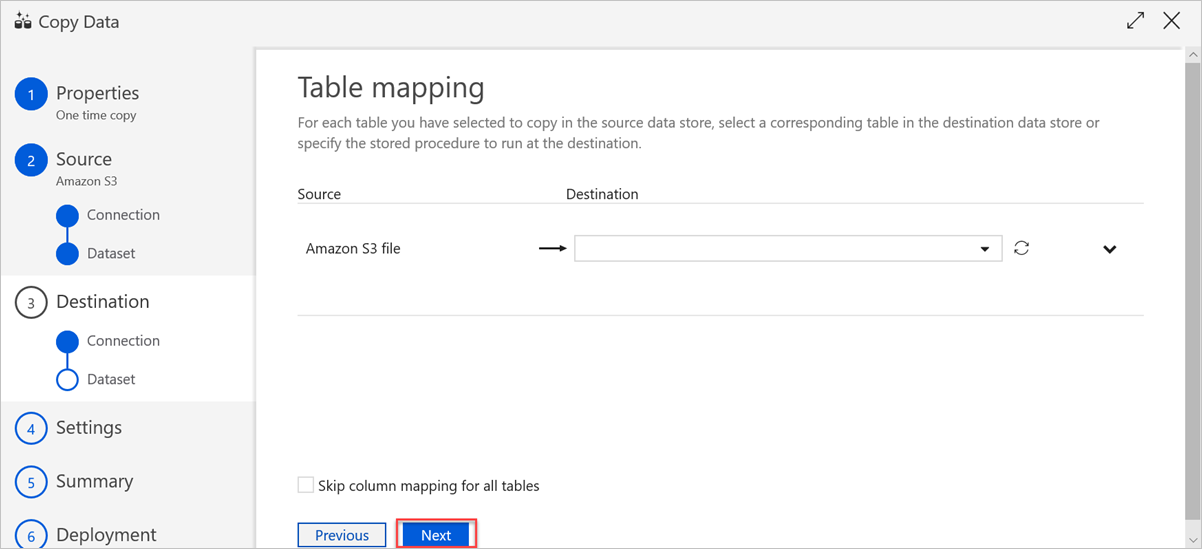
在“表映射”窗格中设置目标表名称,然后选择“下一步”。
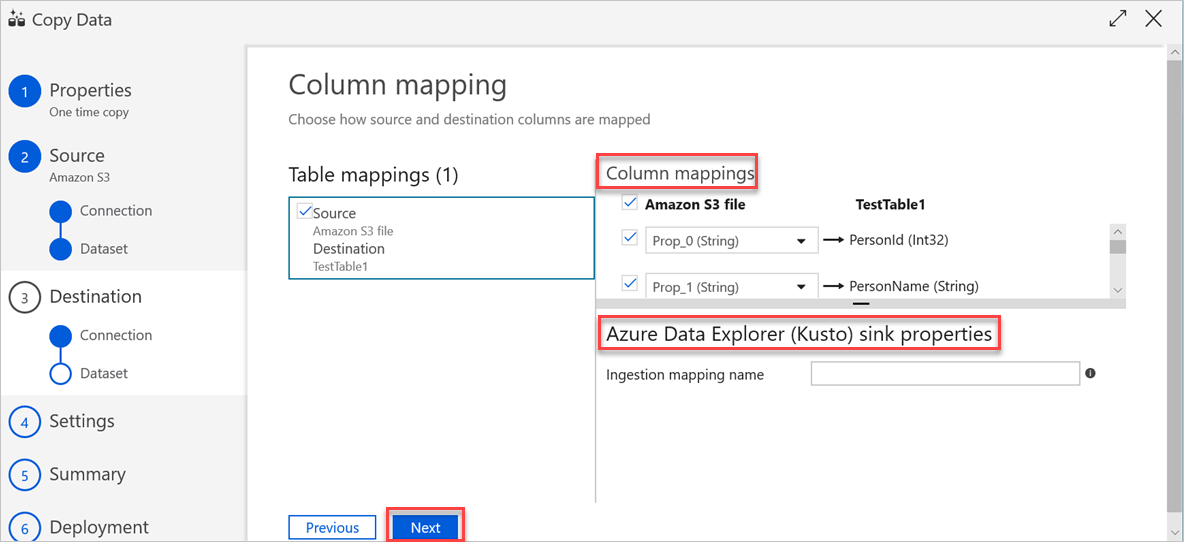
在“列映射”窗格中,将发生以下映射:
a。 第一个映射由 Azure 数据工厂根据 Azure 数据工厂架构映射执行。 请执行以下操作:
设置 Azure 数据工厂目标表的列映射。 将显示从源到 Azure 数据工厂目标表的默认映射。
取消选择不需要定义列映射的列。
b. 将此表格数据引入 Azure 数据资源管理器时,会发生第二个映射。 映射是根据 CSV 映射规则执行的。 即使源数据不采用 CSV 格式,Azure 数据工厂也会将数据转换为表格格式。 因此,在此阶段,只有 CSV 映射才是相关的映射。 请执行以下操作:
(可选)在“Azure 数据资源管理器(Kusto)接收器属性”下,添加相关的“引入映射名称”,以便可以使用列映射。
如果未指定“引入映射名称”,将使用“列映射”部分定义的“按名称”映射顺序。 如果按名称映射失败,Azure 数据资源管理器会尝试以按列位置的顺序引入数据(即默认按位置映射)。
选择“下一步”。
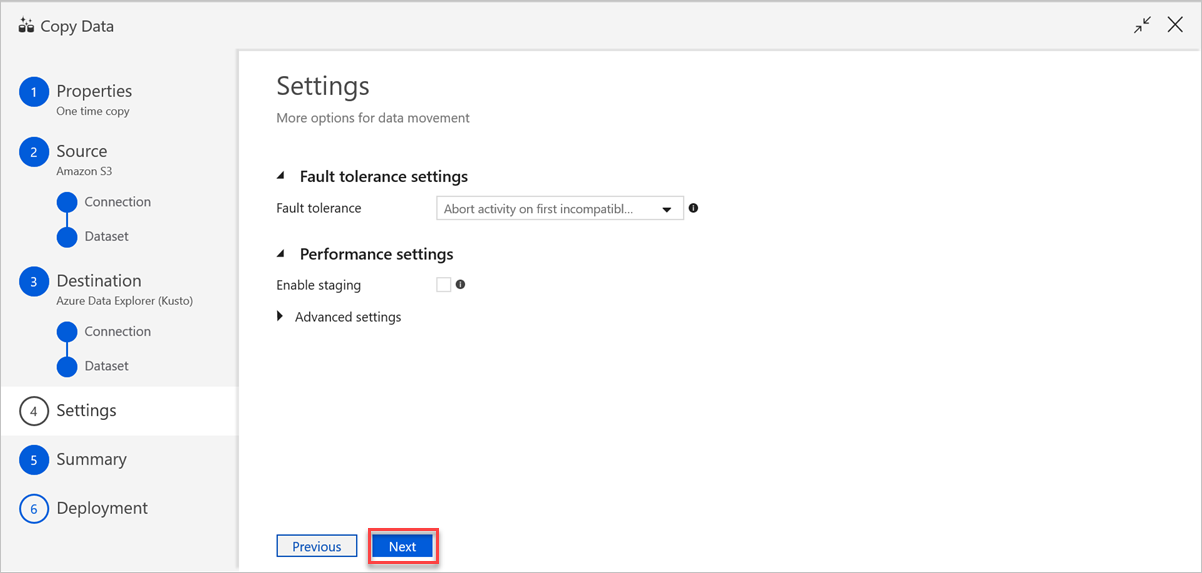
在“设置”窗格中执行以下步骤:
a。 在“容错设置”下,输入相关设置。
b. 在“性能设置”下,“启用暂存”的选项不适用,“高级设置”包括成本考虑因素。 如果没有具体的要求,请将这些设置保留原样。
选项c. 选择“下一步”。
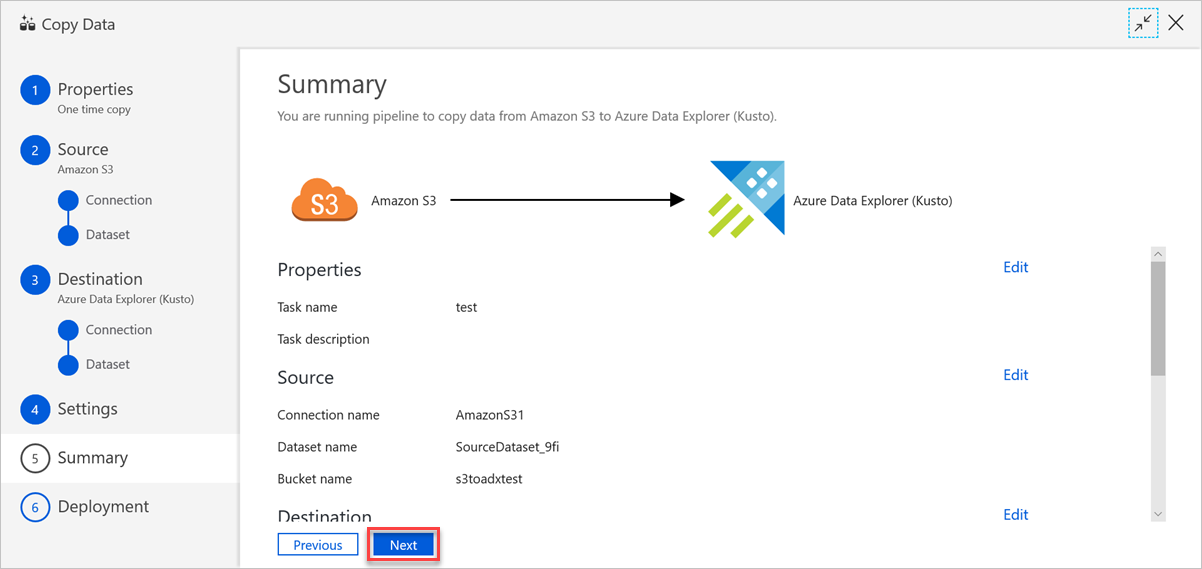
在“摘要”窗格中检查设置,然后选择“下一步”。
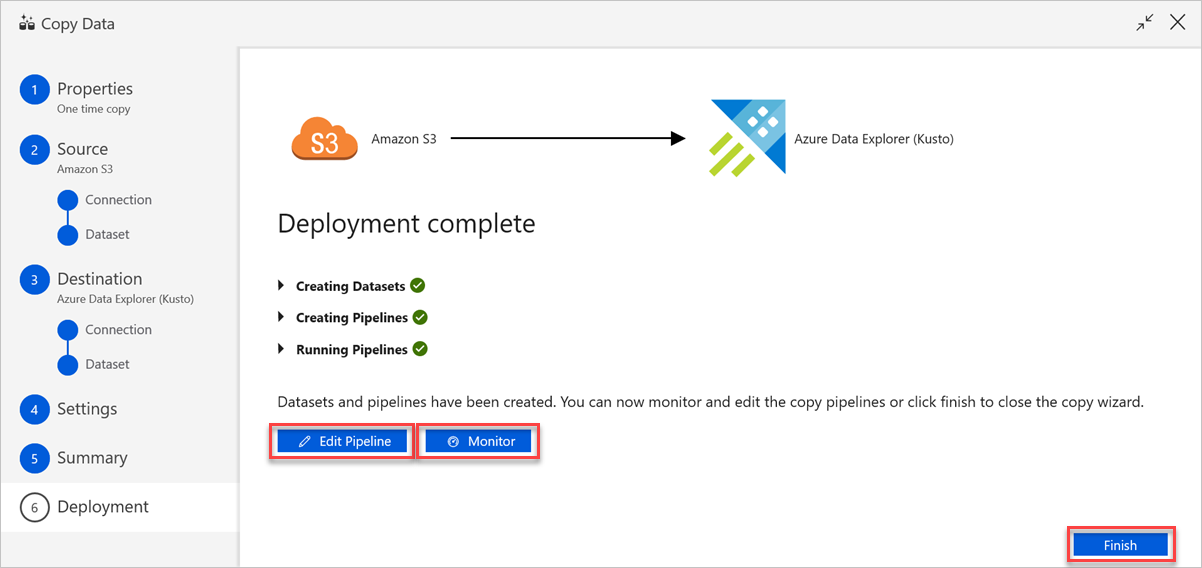
在“部署已完成”窗格中执行以下操作:
a。 若要切换到“监视”选项卡并查看管道的状态(进度、错误和数据流),选择“监视”。
b. 若要编辑链接服务、数据集和管道,请选择“编辑管道”。
选项c. 选择“完成”以完成数据复制任务。
相关内容
- 了解适用于 Azure 数据工厂中 Azure 数据资源管理器连接器。
- 在数据工厂 UI 中编辑链接服务、数据集和管道。
- 在 Azure 数据资源管理器 Web UI 中查询数据。