AKS 监视需要跨平台指标、Prometheus 指标、活动日志、资源日志和容器见解的多个可观测性级别。 AKS 提供内置监视功能,并与 Azure Monitor、容器见解、Prometheus 托管服务和 Azure 托管 Grafana 集成,用于全面的群集运行状况和性能监视。
https://docs.azure.cn/azure-monitor/logs/logs-ingestion-api-overview
洞见
Azure 中的某些服务在 Azure 门户中具有内置的监视仪表板,可以从此入手来监视服务。 这些仪表板称为见解,可在 Azure 门户中 Azure Monitor 的见解中心找到。
AKS 监视数据:指标、日志、集成
AKS 生成与其他 Azure 资源相同的监视数据,如 Azure 资源中的“监视数据”中所述。 有关 AKS 创建的指标和日志的详细信息,请参阅 AKS 监视数据参考。
如下面的示意图和表格所示,其他 Azure 服务和功能会收集其他数据并启用其他分析选项。

| 来源 | 说明 |
|---|---|
| 平台指标 | 系统会自动免费收集 AKS 群集的平台指标。 可以使用 指标资源管理器 分析这些指标,也可以使用它们来创建 指标警报。 |
| 活动日志 | Azure Monitor 活动日志 会自动收集 AKS 群集的某些数据,不收费。 这些日志文件跟踪创建群集或更改群集配置时等信息。 若要使用其他日志数据分析活动日志数据, 请将活动日志数据发送到 Log Analytics 工作区。 |
| 资源日志 | AKS 的控制平面日志实现为资源日志。 创建诊断设置,将日志发送到 Log Analytics 工作区。 在工作区中,可以使用查询分析日志,并根据日志信息设置警报。 |
| 容器洞察 | 容器见解从群集收集各种日志和性能数据,并将其存储在 Log Analytics 工作区 和 Azure Monitor 指标中。 在容器见解或stdout和stderr中,使用视图和工作簿分析数据(如和流)。 |
| Application Insights | Application Insights 是 Azure Monitor 的一项功能,可收集日志、指标和分布式跟踪。 遥测存储在 Log Analytics 工作区 中,以便在 Azure 门户中进行分析。 要通过更改代码来启用 Application Insights,请参阅启用 Azure Monitor OpenTelemetry。 要在不更改代码的情况下启用 Application Insights,请参阅 AKS 自动检测。 有关仪器的详细信息,请了解 数据收集基础知识。 |
资源类型
Azure 使用资源类型和 ID 的概念来标识订阅中的所有内容。 同样的,Azure Monitor 根据资源类型(也称为“命名空间”)将核心监视数据组织为指标和日志。 不同的指标和日志可用于不同的资源类型。 服务可能与多种资源类型关联。
资源类型也是 Azure 中运行的每个资源的资源 ID 的一部分。 例如,虚拟机的一种资源类型是 Microsoft.Compute/virtualMachines。 有关服务及其关联资源类型的列表,请参阅资源提供程序。
有关 AKS 中的资源类型的详细信息,请参阅 AKS 监视数据参考。
数据存储
对于 Azure Monitor:
- 指标数据存储在 Azure Monitor 指标数据库中。
- 日志数据存储在 Azure Monitor 日志存储中。 Log Analytics 是 Azure 门户中可以查询此存储的工具。
- Azure 活动日志是一个单独的存储区,在 Azure 门户中有自己的接口。
- 可选择将指标和活动日志数据路由到 Azure Monitor 日志数据库存储,以便可使用 Log Analytics 查询数据并将其与其他日志数据关联。
有关 Azure Monitor 如何存储数据的详细信息,请参阅 Azure Monitor 数据平台。
Azure Monitor 平台指标
Azure Monitor 为大多数服务提供平台指标。 这些指标是:
- 针对每个命名空间单独定义。
- 存储在 Azure Monitor 时序指标数据库中。
- 轻量级,并支持近实时告警。
- 用于跟踪资源随时间推移的性能变化。
集合:Azure Monitor 会自动收集平台指标。 不需要任何配置。
路由:通常还可将平台指标路由到 Azure Monitor 日志/Log Analytics,从而可以使用其他日志数据对其进行查询。 有关详细信息,请参阅指标诊断设置。 有关如何为服务配置诊断设置,请参阅在 Azure Monitor 中创建诊断设置。
有关可以为 Azure Monitor 中的所有资源收集的所有指标的列表,请参阅 Azure Monitor 中支持的指标。
有关可以为 AKS 收集的指标列表,请参阅 AKS 监视数据参考。
指标在监视群集、识别问题和优化 AKS 群集中的性能方面发挥着重要作用。 平台指标是使用命名空间中 kube-system 安装的现装指标服务器捕获的,该服务器会定期从 kubelet 提供的所有 AKS 节点中抓取指标。 还应为 Prometheus 指标启用托管服务,以收集容器指标和 Kubernetes 对象指标,包括对象部署状态。
可以查看 Prometheus 指标的默认托管服务列表。
有关详细信息,请参阅 从 AKS 群集收集 Prometheus 指标的托管服务。
基于非 Azure Monitor 的指标
此服务提供 Azure Monitor 指标数据库中不包含的其他指标。
可以使用以下 Azure 服务和 Azure Monitor 功能监视 AKS 群集。 创建 AKS 群集时启用这些功能。
在 Azure 门户中,使用 “集成 ”选项卡,或使用 Azure CLI、Terraform 或 Azure Policy。 在某些情况下,可以在创建群集后将群集加入监视服务或功能。 每个服务或功能可能会产生成本,因此在启用每个组件之前,请查看每个组件的定价信息。
| 服务或功能 | 说明 |
|---|---|
| 容器洞察 | 使用容器化版本的Azure Monitor 代理从群集中的每个节点收集stdout和stderr日志以及 Kubernetes 事件。 该功能支持多种 AKS 群集监视场景。 使用 Azure CLI、 Azure Policy、Azure 门户或 Terraform 创建 AKS 群集时,可以启用对 AKS 群集的监视。 如果在创建群集时未启用容器见解,请参阅 为 AKS 群集启用容器见解 以获取其他选项以启用它。容器见解将其大部分数据存储在 Log Analytics 工作区中。 通常会使用与群集的资源日志相同的 Log Analytics 工作区。 有关应使用多少个工作区以及查找位置的指南,请参阅 设计 Log Analytics 工作区体系结构。 |
| Azure 托管的 Grafana | Grafana 的完全托管实现。 Grafana 是一个开源数据可视化平台,通常用于呈现 Prometheus 数据。 可选择多种预定义的 Grafana 仪表板来监视 Kubernetes 并进行全堆栈故障排除。 如果在创建群集时未启用 Azure 托管 Grafana,请参阅 链接 Grafana 工作区。 你可以将其链接到 Azure Monitor 工作区,以便它可以从群集访问 Prometheus 指标。 |
AKS 控制平面资源日志
先决条件:需要 AKS 群集所在的同一订阅中的 Log Analytics 工作区。 目标工作区的资源日志会产生引入和保留成本。 若要进行成本优化,请使用特定于资源的模式,并为审核表配置基本日志层。
AKS 群集的控制平面日志在 Azure Monitor 中以资源日志的形式实现。 在创建诊断设置以将资源日志路由到至少一个位置之前,不会收集并存储资源日志。 通常会将资源日志发送到 Log Analytics 工作区,其中存储了容器见解的大多数数据。
若要了解如何使用 Azure 门户、Azure CLI 或 Azure PowerShell 创建诊断设置,请参阅 “创建诊断设置”。 创建诊断设置时,请指定要收集的日志类别。 AKS 监视数据参考中列出了 AKS 的类别。
警告
为 AKS 收集资源日志时,尤其是 Kube-audit 日志,可能会产生大量成本。 请考虑以下建议以减少收集的数据量:
- 在不需要时禁用
kube-audit日志记录。 - 启用从
kube-audit-admin收集数据,但排除get和list审核事件。 - 按照本文中所述启用特定于资源的日志,并将 AKSAudit 表配置为 基本日志。
有关更多监视建议,请参阅 使用 Azure 服务和云原生工具监视 AKS 群集。 有关降低监视成本的策略,请参阅 成本优化和 Azure Monitor。
对于资源日志,AKS 支持 Azure 诊断模式或特定于资源的模式。 Azure 诊断模式将所有数据发送到 AzureDiagnostics 表。 资源特定的模式指定发送数据的 Log Analytics 工作区中的表。 它还将数据发送到AKSAuditAKSAuditAdminAKSControlPlane资源日志中的表所示。
出于以下原因,建议对 AKS 使用特定于资源的模式:
- 数据更易于查询,因为它位于专用于 AKS 的单个表中。
- 资源专用模式允许配置为 基本日志,以大幅度节省成本。
有关集合模式之间的差异的详细信息,包括如何更改现有设置,请参阅 “选择收集模式”。
注意
可以使用 Azure CLI 配置诊断设置。 此方法不能保证成功,因为它不会检查群集的预配状态。 更改诊断设置后,请检查以确保群集反映设置更改。
az monitor diagnostic-settings create --name AKS-Diagnostics --resource /subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourceGroups/myresourcegroup/providers/Microsoft.ContainerService/managedClusters/my-cluster --logs '[{"category": "kube-audit","enabled": true}, {"category": "kube-audit-admin", "enabled": true}, {"category": "kube-apiserver", "enabled": true}, {"category": "kube-controller-manager", "enabled": true}, {"category": "kube-scheduler", "enabled": true}, {"category": "cluster-autoscaler", "enabled": true}, {"category": "cloud-controller-manager", "enabled": true}, {"category": "guard", "enabled": true}, {"category": "csi-azuredisk-controller", "enabled": true}, {"category": "csi-azurefile-controller", "enabled": true}, {"category": "csi-snapshot-controller", "enabled": true}]' --workspace /subscriptions/xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx/resourcegroups/myresourcegroup/providers/microsoft.operationalinsights/workspaces/myworkspace --export-to-resource-specific true
AKS 资源日志查询和示例
查询范围要求:在 AKS 群集菜单上选择 “日志 ”时,Log Analytics 会打开,并将查询范围设置为当前群集。 日志查询仅包含来自该资源的数据。 若要运行包含来自其他群集或 Azure 服务的数据的查询,请从 Azure Monitor 菜单中选择“日志”。
如果 群集的诊断设置 使用 Azure 诊断模式,则 AKS 的资源日志存储在 AzureDiagnostics 表中。 在“类别”列中确认日志。 有关每个类别的说明,请参阅 AKS 参考资源日志。
| 说明 | 模式 | 日志查询 |
|---|---|---|
| 统计各类别的日志数量 | Azure 诊断模式 | AzureDiagnostics| where ResourceType == "MANAGEDCLUSTERS"| summarize count() by Category |
| 所有 API 服务器日志 | Azure 诊断模式 | AzureDiagnostics| where Category == "kube-apiserver" |
| 某个时间范围内的所有 kube-audit 日志 | Azure 诊断模式 | let starttime = datetime("2023-02-23");let endtime = datetime("2023-02-24");AzureDiagnostics| where TimeGenerated between(starttime..endtime)| where Category == "kube-audit"| extend event = parse_json(log_s)| extend HttpMethod = tostring(event.verb)| extend User = tostring(event.user.username)| extend Apiserver = pod_s| extend SourceIP = tostring(event.sourceIPs[0])| project TimeGenerated, Category, HttpMethod, User, Apiserver, SourceIP, OperationName, event |
| 所有审核日志 | 特定于资源的模式 | AKSAudit |
排除 get 和 list 审核事件的所有审核日志 |
特定于资源的模式 | AKSAuditAdmin |
| 所有 API 服务器日志 | 特定于资源的模式 | AKSControlPlane| where Category == "kube-apiserver" |
若要访问 Log Analytics 工作区中的一组预生成查询,请参阅 Log Analytics 查询接口,并选择 Kubernetes 服务 资源类型。 请参阅容器见解查询,查看容器见解常见查询的列表。
AKS 审核策略
AKS 使用 Kubernetes 审核策略 来控制记录的事件及其包含的数据。 该策略定义规则,这些规则根据用户、资源、命名空间和谓词确定不同类型的 API 请求的审核级别。 使用以下审核级别:
- 无:不记录与此规则匹配的事件。
- 元数据:日志请求元数据(请求用户、时间戳、资源、谓词),但不请求或响应正文。
- 请求:记录事件元数据和请求正文,但不记录响应正文。
- RequestResponse:记录事件元数据、请求和响应正文。
下表总结了 AKS 中应用的关键审核策略规则:
| 审核级别 | 说明 | 示例事件 |
|---|---|---|
| 没有 | 高量、低风险的读取操作 |
aksService 用户 get/list 操作,kube-proxy 监控终结点/服务,kubelet get 节点/节点状态,健康检查 URL(/healthz*,/version,/swagger*) |
| 元数据 | 系统事件、事件资源(除了default、/ 和kube-system中的创建/更新)、机密信息、配置映射、服务帐户、令牌审核 |
令牌评审、机密/配置映射访问、大型 CRD,例如 installations.operator.tigera.io |
| 请求 | kubelets/nodes 中的节点和 Pod 状态更新、删除集合操作、卷快照的 CRD 更新、核心 API 组上的读取操作(get/list/watch)、VPA 更改 |
Kubelet 状态更新、命名空间删除、VPA 检查点更新 |
| RequestResponse | CoreDNS 自定义配置映射更新、舰队 API 操作、Karpenter 资源更改、核心 API 组上所有其他写入操作 | CoreDNS 配置更改、机群成员集群操作、Karpenter 节点池更改 |
AKS 中使用的完整审核策略可在以下可折叠部分中查看。
查看完整的 AKS 审核策略
apiVersion: audit.k8s.io/v1
kind: Policy
rules:
# audit level 'None' for high volume and low risk events
- level: None
users: ["aksService"]
verbs: ["get", "list"]
# audit level 'None' for low-risk requests
- level: None
users: ["system:kube-proxy"]
verbs: ["watch"]
resources:
- group: ""
resources: ["endpoints", "services", "services/status"]
# audit level 'None' for low-risk requests
- level: None
users: ["kubelet"] # legacy kubelet identity
verbs: ["get"]
resources:
- group: ""
resources: ["nodes", "nodes/status"]
# audit level 'None' for low-risk requests
- level: None
userGroups: ["system:nodes"]
verbs: ["get"]
resources:
- group: ""
resources: ["nodes", "nodes/status"]
# audit level 'None' for low-risk requests
- level: None
users:
- aksService # the default user/cert used by aks in master node
- system:serviceaccount:kube-system:endpoint-controller
verbs: ["get", "update"]
namespaces: ["kube-system"]
resources:
- group: ""
resources: ["endpoints"]
# audit level 'None' for low-risk requests
- level: None
users: ["system:apiserver"]
verbs: ["get"]
resources:
- group: ""
resources: ["namespaces", "namespaces/status", "namespaces/finalize"]
# audit level 'None' for low-risk requests
- level: None
users:
- aksService # the default user/cert used by aks in master node
verbs: ["get", "list"]
resources:
- group: "metrics.k8s.io"
# Don't log these read-only URLs.
- level: None
nonResourceURLs:
- /healthz*
- /version
- /swagger*
# monitor metadata for system events which are being logged by eventlogger component
- level: Metadata
verbs: ["create", "update", "patch"]
resources:
- group: ""
resources: ["events"]
- group: "events.k8s.io"
resources: ["events"]
namespaces: ["default", "kube-system"]
# Monitoring of actions to detect security/performance relevant activities.
- level: Metadata
verbs: ["delete", "list"]
resources:
- group: ""
resources: ["events"]
- group: "events.k8s.io"
resources: ["events"]
# Don't log other events requests.
- level: None
resources:
- group: ""
resources: ["events"]
- group: "events.k8s.io"
resources: ["events"]
# node and pod status calls from nodes are high-volume and can be large, don't log responses for expected updates from nodes
- level: Request
users: ["client", "kubelet", "system:node-problem-detector", "system:serviceaccount:kube-system:node-problem-detector", "system:serviceaccount:kube-system:aci-connector-linux"]
verbs: ["update","patch"]
resources:
- group: ""
resources: ["nodes/status", "pods/status"]
omitStages:
- "RequestReceived"
# node and pod status calls from nodes are high-volume and can be large, don't log responses for expected updates from nodes
- level: Request
userGroups: ["system:nodes"]
verbs: ["update","patch"]
resources:
- group: ""
resources: ["nodes/status", "pods/status"]
omitStages:
- "RequestReceived"
# deletecollection calls can be large, don't log responses for expected namespace deletions
- level: Request
users: ["system:serviceaccount:kube-system:namespace-controller"]
verbs: ["deletecollection"]
omitStages:
- "RequestReceived"
# ignore response object that has big size
- level: Request
verbs: ["update","patch"]
resources:
- group: "apiextensions.k8s.io"
resources: ["customresourcedefinitions"]
resourceNames: ["volumesnapshotcontents.snapshot.storage.k8s.io", "volumesnapshots.snapshot.storage.k8s.io"]
omitStages:
- "RequestReceived"
# ignore request and response objects for large CRDs that will be filtered down anyway
- level: Metadata
resources:
- group: "apiextensions.k8s.io"
resources: ["customresourcedefinitions"]
resourceNames: ["installations.operator.tigera.io"]
omitStages:
- "RequestReceived"
# overriding the default behavior of coredns might have security threats for Kubernetes DNS in security perspective, set the level as RequestResponse
- level: RequestResponse
verbs: ["update","patch"]
resources:
- group: ""
resources: ["configmaps"]
resourceNames: ["coredns-custom"]
namespaces: ["kube-system"]
omitStages:
- "RequestReceived"
# Secrets, ConfigMaps, ServiceAccounts, TokenRequest and TokenReviews can contain sensitive & binary data,
# so only log at the Metadata level.
- level: Metadata
resources:
- group: ""
resources: ["secrets", "configmaps", "serviceaccounts", "serviceaccounts/token"]
- group: authentication.k8s.io
resources: ["tokenreviews"]
omitStages:
- "RequestReceived"
# Capture state of vertical pod autoscalers
- level: Request
verbs: ["create", "update", "patch", "delete"]
resources:
- group: "autoscaling.k8s.io"
resources: ["verticalpodautoscalers", "verticalpodautoscalercheckpoints"]
omitStages:
- "RequestReceived"
# Capture create and delete of internal fleet resources
- level: RequestResponse
verbs: ["create", "delete"]
resources:
- group: "cluster.kubernetes-fleet.io"
resources: ["memberclusters", "internalmemberclusters"]
- group: "placement.kubernetes-fleet.io"
resources: ["works"]
- group: "networking.fleet.azure.com"
resources: ["internalserviceexports", "internalserviceimports"]
omitStages:
- "RequestReceived"
# Capture CUD of user facing Fleet API
- level: RequestResponse
verbs: ["create", "update", "patch", "delete"]
resources:
- group: "placement.kubernetes-fleet.io"
resources: ["clusterstagedupdateruns", "clusterresourceplacements", "clusterresourceplacementevictions", "clusterresourceplacementdisruptionbudgets", "clusterstagedupdatestrategies", "clusterapprovalrequests", "clusterresourceoverrides", "resourceoverrides"]
- group: "networking.fleet.azure.com"
resources: ["serviceexports", "multiclusterservices", "trafficmanagerprofiles", "trafficmanagerbackends"]
omitStages:
- "RequestReceived"
# Capture CUD of user facing Karpenter resources
- level: RequestResponse
verbs: ["create", "update", "patch", "delete"]
resources:
- group: "karpenter.azure.com"
resources: ["aksnodeclasses", "aksnodeclasses/status"]
- group: "karpenter.sh"
resources: ["nodepools", "nodepools/status", "nodeclaims", "nodeclaims/status"]
omitStages:
- "RequestReceived"
# Get responses can be large; don't log response
- level: Request
verbs: ["get", "list", "watch"]
resources:
- group: ""
- group: "admissionregistration.k8s.io"
- group: "apiextensions.k8s.io"
- group: "apiregistration.k8s.io"
- group: "apps"
- group: "authentication.k8s.io"
- group: "authorization.k8s.io"
- group: "autoscaling"
- group: "batch"
- group: "certificates.k8s.io"
- group: "extensions"
- group: "metrics.k8s.io"
- group: "networking.k8s.io"
- group: "policy"
- group: "rbac.authorization.k8s.io"
- group: "scheduling.k8s.io"
- group: "settings.k8s.io"
- group: "storage.k8s.io"
omitStages:
- "RequestReceived"
# Default level for known APIs
- level: RequestResponse
resources:
- group: ""
- group: "admissionregistration.k8s.io"
- group: "apiextensions.k8s.io"
- group: "apiregistration.k8s.io"
- group: "apps"
- group: "authentication.k8s.io"
- group: "authorization.k8s.io"
- group: "autoscaling"
- group: "batch"
- group: "certificates.k8s.io"
- group: "extensions"
- group: "metrics.k8s.io"
- group: "networking.k8s.io"
- group: "policy"
- group: "rbac.authorization.k8s.io"
- group: "scheduling.k8s.io"
- group: "settings.k8s.io"
- group: "storage.k8s.io"
omitStages:
- "RequestReceived"
# Default level for all other requests.
- level: Metadata
omitStages:
- "RequestReceived"
注意
审核策略由 AKS 管理,无法自定义。 该策略旨在通过减少高频率、低风险操作的日志量,实现安全可观测性与性能和成本优化的平衡。
AKS 数据平面容器见解日志
先决条件和配置要求:容器见解需要 Log Analytics 工作区进行日志存储,并支持托管标识和旧式身份验证方法。 对于新群集,建议使用托管标识身份验证。 可以使用 Azure Monitor 数据收集规则(DCR)自定义数据收集,以控制成本并减少引入量。
容器见解从容器和 AKS 群集收集各种类型的遥测数据,以帮助监视、故障排除和深入了解 AKS 群集中运行的容器化应用程序。 有关容器见解所使用的表列表及其详细说明,请参阅 Azure Monitor 表格引用。 所有表都可用于 日志查询。
使用 成本优化设置 自定义和控制通过容器见解代理收集的指标数据。 此功能支持单个表选择、数据收集间隔和命名空间的数据收集设置,以通过 Azure Monitor 数据收集规则(DCR)排除数据收集。 这些设置控制数据引入量并降低容器洞察的监控成本。 在 Azure 门户中,可以使用以下功能选项自定义容器洞察收集的数据。 选择 除“全部”以外的任何选项(默认值) 会使容器见解体验不可用。
| 分组 | 表 | 说明 |
|---|---|---|
| 全部(默认值) | 所有标准容器分析信息表 | 必须启用默认的容器洞察图形化效果。 |
| Performance | Perf、InsightsMetrics | N/A |
| 日志和事件 | ContainerLog 或 ContainerLogV2,KubeEvents,KubePodInventory | 如果为 Prometheus 指标启用了托管服务,则建议使用。 |
| 工作负荷、部署和 HPA | InsightsMetrics、KubePodInventory、KubeEvents、ContainerInventory、ContainerNodeInventory、KubeNodeInventory、KubeServices | N/A |
| 永久性卷 | InsightsMetrics、KubePVInventory | N/A |
日志和事件分组从 ContainerLog 或 ContainerLogV2、KubeEvents 和 KubePodInventory 表中捕获日志,但不会捕获度量数据。 收集指标的建议路径是从 AKS 群集 启用 Prometheus 的托管服务 ,并使用 Azure 托管 Grafana 进行数据可视化。 有关详细信息,请参阅管理 Azure Monitor 工作区
ContainerLogV2 架构
兼容性和配置要求:对于通过 Azure 资源管理器(ARM)模板、Bicep、Terraform、Azure Policy 或 Azure 门户使用托管标识进行身份验证的新容器监控部署,建议使用 ContainerLogV2 架构。 该架构与基本日志层兼容,可节省成本,不会影响分析或警报功能。 有关如何通过群集的 DCR 或 configmap 启用 ContainerLogV2 的详细信息,请参阅 “启用 ContainerLogV2 架构”。
Azure Monitor 中的容器见解为容器日志 ContainerLogV2 提供了建议的架构。 格式包括以下字段,以便常用查询可以查看与 AKS 和已启用 Azure Arc 的 Kubernetes 群集相关的数据:
- ContainerName
- PodName
- PodNamespace
Azure 活动日志
活动日志包含订阅级事件,这些事件跟踪从资源外部看到的每个 Azure 资源的操作;例如,创建新资源或启动虚拟机。
收集:活动日志事件会自动生成并收集在单独的存储中,以便在 Azure 门户中查看。
路由:可将活动日志数据发送到 Azure Monitor 日志,以便可以将它们与其他日志数据一起进行分析。 其他位置(例如 Azure 存储、Azure 事件中心和某些 Azure 监视合作伙伴)也可用。 有关如何路由活动日志的详细信息,请参阅 Azure 活动日志概述。
实时查看 AKS 容器日志、事件和 Pod 指标
先决条件和设置要求:实时数据功能要求在群集上启用容器见解并使用直接 Kubernetes API 访问。 对于专用群集,访问需要与群集位于同一专用网络中的计算机。 身份验证遵循 Kubernetes RBAC 模型,需要适当的群集权限。
可以使用容器见解中的 实时数据 功能查看 AKS 容器日志、事件和 Pod 指标,并通过直接访问 kubectl logs -c、kubectl get 事件和 kubectl top pods 实时排查问题。
注意
AKS 使用 Kubernetes 群集级日志记录体系结构。 容器日志位于 /var/log/containers 节点上。 若要访问节点,请参阅 “连接到 AKS 群集节点”。
若要了解如何设置此功能,请参阅 在容器见解中配置实时数据。 该功能直接访问 Kubernetes API。 有关身份验证模型的详细信息,请参阅 Kubernetes API。
查看 AKS 资源实时日志
专用群集网络要求:若要从专用群集访问日志,必须使用与群集位于同一专用网络中的计算机。
在 Azure 门户中,转到 AKS 群集。
在“Kubernetes 资源”下,选择“工作负荷”。
对于“部署”、“Pod”、“副本集”、“StatefulSet”、“作业”或“Cron 作业”,选择一个值,然后选择“实时日志”。
选择要查看的资源日志。
以下示例显示了 Pod 资源的日志:
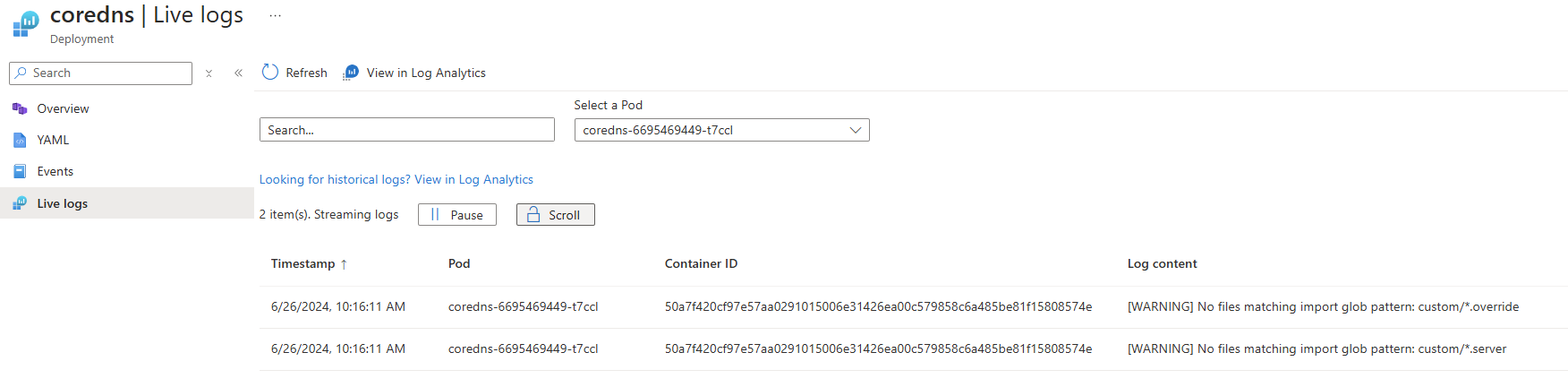

使用容器洞察查看实时容器日志
身份验证和数据流:成功身份验证后,如果可以检索数据,它将开始流式传输到 “实时日志 ”选项卡。日志数据显示在连续流中。 可通过 Log Analytics 中的“查看日志 ”进行备用日志访问,以便进行历史分析。
可以在容器引擎在 “群集”、“ 节点”、“ 控制器”或“ 容器 ”选项卡上生成实时日志数据。
在 Azure 门户中,转到 AKS 群集。
在监控下,选择见解。
在 “群集”、“ 节点”、“ 控制器”或“ 容器 ”选项卡上,选择一个值。
在资源的 “概述 ”窗格中,选择“ 实时日志”。
下图显示了容器资源的日志:
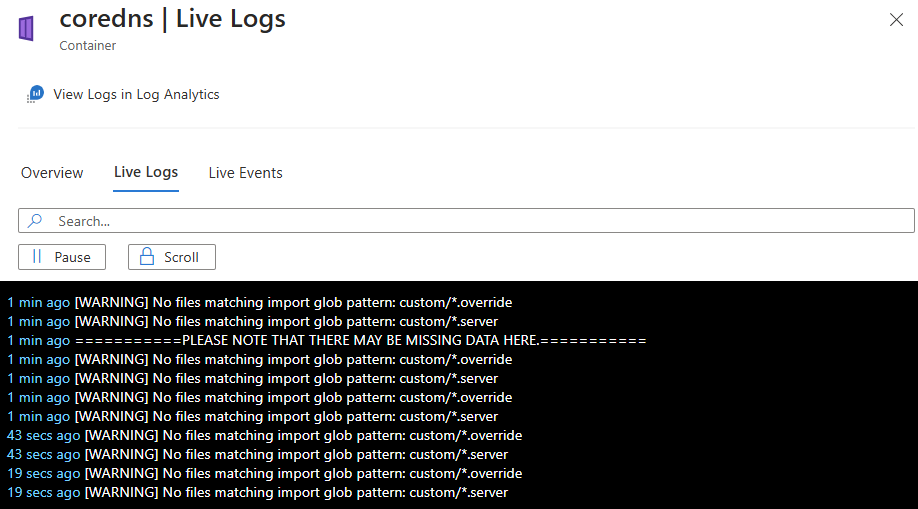

使用容器洞察查看容器实时事件
事件流式处理和访问:容器引擎生成实时事件数据流。 事件包括 Pod 创建、删除、缩放操作以及错误条件。 历史事件数据可通过 Log Analytics 中的“查看事件”访问。
可以在容器引擎在 “群集”、“ 节点”、“ 控制器”或“ 容器 ”选项卡上生成实时事件数据。
在 Azure 门户中,转到 AKS 群集。
在监控下,选择见解。
选择 “群集”、“ 节点”、“ 控制器”或“ 容器 ”选项卡,然后选择一个对象。
在“资源 概述 ”窗格中,选择“ 实时事件”。
成功身份验证后,如果可以检索数据,它将开始流式传输到 “实时事件 ”选项卡。下图显示了容器资源的事件:
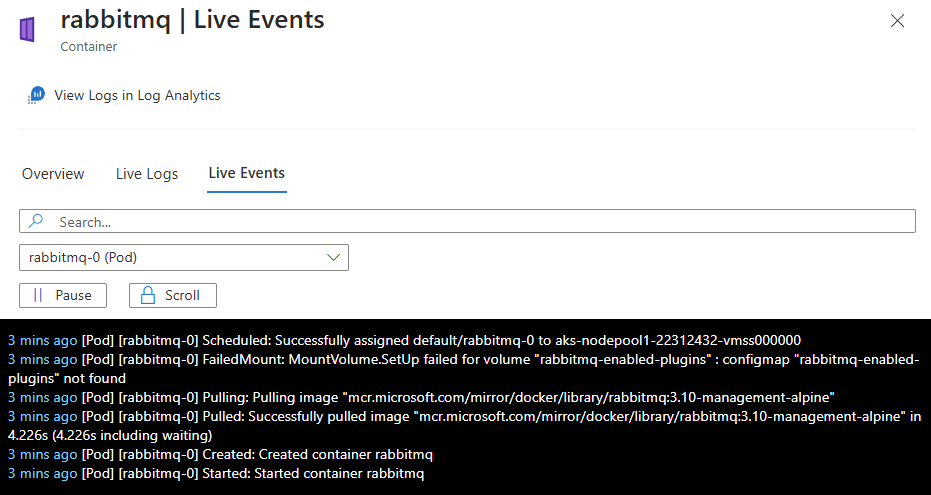

使用容器洞察查看 Pod 实时指标
指标范围和可用性:实时指标可用于 “节点 ”或“ 控制器 ”选项卡上的 Pod 资源。 指标包括 CPU 使用率、内存消耗、网络 I/O 和文件系统统计信息。 历史指标可通过 Log Analytics 中的“查看事件”访问。
可以在“节点”或“控制器”选项卡中,通过选择 Pod 资源查看容器引擎生成的实时指标数据。
在 Azure 门户中,转到 AKS 群集。
在监控下,选择洞察。
选择 “节点 或 控制器 ”选项卡,然后选择 Pod 对象。
在“资源 概述 ”窗格中,选择“ 实时指标”。
成功身份验证后,如果可以检索数据,它将开始流式传输到 “实时指标 ”选项卡。下图显示了 Pod 资源的指标:
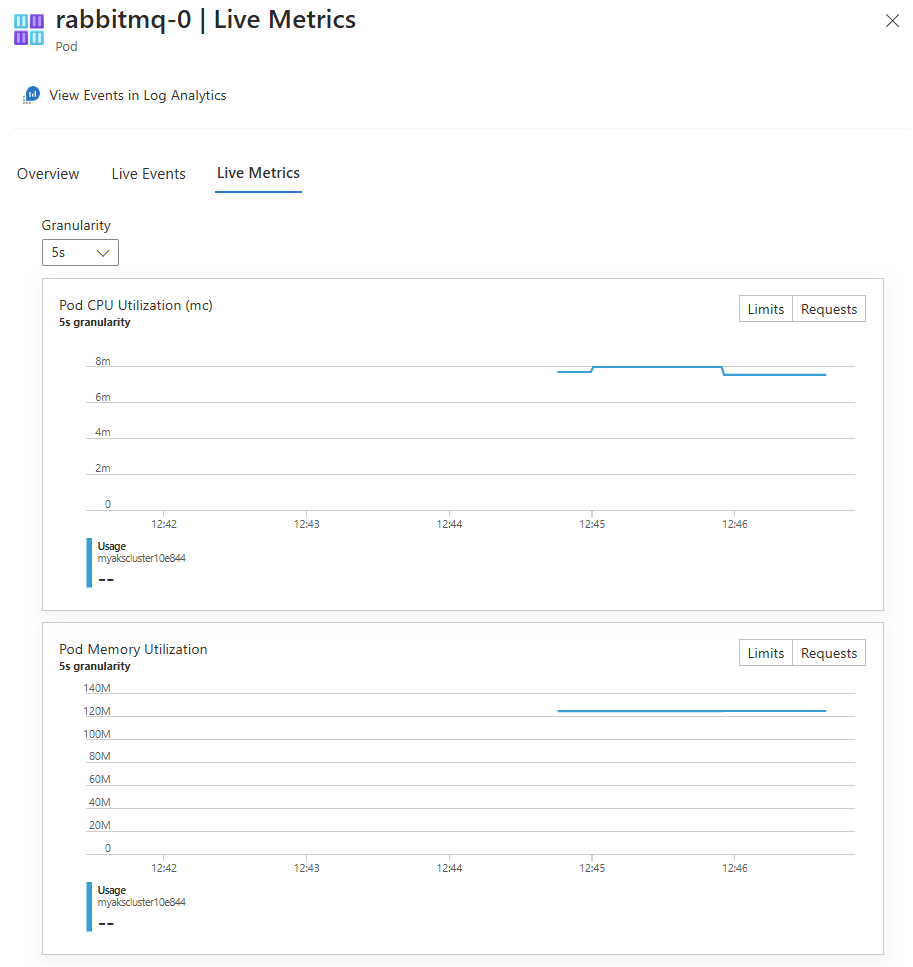

分析监视数据
有许多工具可用于分析监视数据。
Azure Monitor 工具
Azure Monitor 支持以下基本工具:
指标资源管理器,它是 Azure 门户中的工具,可用于查看和分析 Azure 资源的指标。 有关详细信息,请参阅使用 Azure Monitor 指标资源管理器分析指标。
Log Analytics,它是 Azure 门户中的一种工具,支持使用 Kusto 查询语言 (KQL) 来查询和分析日志数据。 有关详细信息,请参阅 Azure Monitor 日志查询入门。
活动日志,它在 Azure 门户中具有用于执行查看和基本搜索的用户界面。 要进行更深入的分析,必须将数据路由到 Azure Monitor 日志,并在 Log Analytics 中运行更复杂的查询。
支持更复杂可视化效果的工具包括:
- 仪表板,它支持将不同类型的数据合并到 Azure 门户的单个窗格中。
- 工作簿,它们是可在 Azure 门户中创建的可自定义报表。 工作簿可以包括文本、指标和日志查询。
- Power BI,它是一项业务分析服务,可提供跨各种数据源的交互式可视化效果。 可将 Power BI 配置为自动从 Azure Monitor 导入日志数据,以利用这些可视化效果。
Azure Monitor 导出工具
可以使用以下方法将数据从 Azure Monitor 中提取到其他工具中:
指标:使用适用于指标的 REST API 从 Azure Monitor 指标数据库提取指标数据。 API 支持使用筛选表达式优化检索到的数据。 有关详细信息,请参阅 Azure Monitor REST API 参考。
日志:使用 REST API 或关联的客户端库。
要开始使用适用于 Azure Monitor 的 REST API,请参阅 Azure 监视 REST API 演练。
在 Azure 门户中监视 AKS 群集
AKS 群集资源的“概述”窗格中的“监视”选项卡提供了一种快速的方法来开始在 Azure 门户中查看监视数据。 此选项卡显示按节点池划分的群集常见指标图表。 你可以选择其中任意一张图,以在指标资源管理器中进一步分析数据。
“监视”选项卡还包括指向适用于 Prometheus 的 Azure 托管服务的链接,以及群集的容器见解。 可以在“ 监视 ”选项卡上启用这些工具。还可以在窗格顶部看到一个横幅,该横幅建议其他功能来改进群集的监视。
提示
若要访问订阅中所有 AKS 群集的监视功能,请在 Azure 门户主页上选择 Azure Monitor。
使用 AKS 桌面观察和排查应用程序问题
AKS 桌面是一种以应用程序为中心的桌面体验,用于Azure Kubernetes 服务 (AKS),可帮助你连接到群集、查看资源、部署应用程序和对工作负载进行故障排除,而无需深入 Kubernetes 专业知识。
AKS 桌面版对 Azure Monitor 和容器见解形成补充,为应用程序团队提供一个统一的开箱即用平台,用于对各自的应用程序工作负载进行日常的高层级监控和故障排查,而无需构建自定义工具或在多个工具之间切换。
在 AKS 桌面项目中,您可以:
- 查看 应用程序组件的 CPU 和内存消耗等指标。
- 实时流式传输 Pod 日志以供调试。
- 使用资源映射可视化工作负荷和服务之间的依赖关系。

有关详细信息,请参阅 AKS 桌面概述。
Kusto 查询
可使用 Kusto 查询语言 (KQL) 来分析 Azure Monitor 日志/Log Analytics 存储中的监视数据。
重要
在门户的服务菜单中选择“日志”时,会打开 Log Analytics,并且其查询范围设置为当前服务。 此范围意味着日志查询将仅包含来自该资源类型的数据。 如果希望运行的查询包含来自其他 Azure 服务的数据,请从“Azure Monitor”菜单中选择“日志”。 有关详细信息,请参阅 Azure Monitor Log Analytics 中的日志查询范围和时间范围。
有关任何服务的常见查询的列表,请参阅 Log Analytics 查询界面。
警报
在监视数据中发现特定情况时,Azure Monitor 警报会主动向你发出通知。 有了警报,你就可以在客户注意到你的系统中的问题之前找出和解决问题。 有关详细信息,请参阅 Azure Monitor 警报。
Azure 资源的常见警报具有许多来源。 有关 Azure 资源常见警报的示例,请参阅示例日志警报查询。 Azure Monitor 基线警报 (AMBA) 站点提供了 Azure 登陆区域 (ALZ) 场景的关键警报指标、仪表板和指南。
通用警报模式对 Azure Monitor 警报通知的使用体验进行了标准化。 有关详细信息,请参阅常见警报架构。
警报类型
可以针对 Azure Monitor 数据平台中的任何指标或日志数据源发出警报。 警报具有许多不同类型,具体取决于要监视的服务以及要收集的监视数据。 不同类型的警报各有优缺点。 有关详细信息,请参阅选择正确的监视警报类型。
以下列表介绍了可以创建的 Azure Monitor 警报类型:
- 指标警报会定期评估资源指标。 指标可以是平台指标、自定义指标、Azure Monitor 中的日志转换为的指标或 Application Insights 指标。 指标警报还可以应用多个条件和动态阈值。
- 日志警报支持用户使用 Log Analytics 查询按照预定义的频率评估资源日志。
- 当发生匹配所定义条件的新活动日志事件时,会触发活动日志警报。 资源运行状况警报和服务运行状况警报是报告服务和资源运行状况的活动日志警报。
还可以为某些 Azure 服务创建以下类型的警报:
- Application Insights 资源上的智能检测警报会就 Web 应用程序中的潜在性能问题和故障异常自动向你发出警报。 可以在 Application Insights 资源上迁移智能检测,以便为不同的智能检测模块创建警报规则。
- Prometheus 警报:针对 Prometheus 指标的警报,这些指标存储在适用于 Prometheus 的 Azure Monitor 托管服务中。 该警报规则基于 PromQL,它是一种开源查询语言。 你的服务可能不支持此类型警报。 目前,Prometheus 用于具有来宾操作系统的有限服务集,例如 Azure 虚拟机和 Azure 容器实例。
- 对于某些 Azure 资源(包括虚拟机、Azure Kubernetes 服务 [AKS] 资源和 Log Analytics 工作区),提供了现成可用的建议警报规则。
监视多个资源
通过将相同的指标警报规则应用于同一 Azure 区域中的多个相同类型资源,可以进行大规模的监视。 将为每个受监视的资源发送单独通知。 有关支持的 Azure 服务和云,请参阅使用一个警报规则监视多个资源。
建议的预警规则
对于某些 Azure 服务,可以启用推荐的现成警报规则。
系统根据以下内容编译了一个建议的警报规则列表:
- 资源提供者对监控资源的重要信号和阈值的了解。
- 指明客户通常针对此资源的哪些方面设置警报的数据。
注意
建议的警报规则适用于:
- 虚拟机
- Azure Kubernetes 服务 (AKS) 资源
- Log Analytics 工作区
配置基于 Prometheus 指标的警报
下载和配置要求:警报规则可用作可下载的 ARM 模板或 Bicep 文件。 在配置警报之前,请确保群集上启用了 Prometheus 的托管服务,并且 Azure Monitor 工作区已正确链接到 AKS 群集。
为群集启用 Prometheus 指标的托管服务集合时,可以下载推荐的 Prometheus 警报规则托管服务集合。
下载包括以下规则:
| 级别 | 警报 |
|---|---|
| 群集级别 | KubeCPUQuotaOvercommitKubeMemoryQuotaOvercommitKubeContainerOOMKilledCountKubeClientErrorsKubePersistentVolumeFillingUpKubePersistentVolumeInodesFillingUpKubePersistentVolumeErrorsKubeContainerWaitingKubeDaemonSetNotScheduledKubeDaemonSetMisScheduledKubeQuotaAlmostFull |
| 节点级别 | KubeNodeUnreachableKubeNodeReadinessFlapping |
| Pod 级别 | KubePVUsageHighKubeDeploymentReplicasMismatchKubeStatefulSetReplicasMismatchKubeHpaReplicasMismatchKubeHpaMaxedOutKubePodCrashLoopingKubeJobStaleKubePodContainerRestartKubePodReadyStateLowKubePodFailedStateKubePodNotReadyByControllerKubeStatefulSetGenerationMismatchKubeJobFailedKubeContainerAverageCPUHighKubeContainerAverageMemoryHighKubeletPodStartUpLatencyHigh |
有关详细信息,请参阅 从容器见解创建日志警报 ,以及 容器见解中的查询日志。
日志警报 可以测量两种类型的信息,以帮助监视各种方案:
- 结果计数:计算查询返回的行数。 使用此信息来处理 Windows 事件日志、syslog 事件和应用程序异常等事件。
- 值的计算:基于数值列进行计算。 使用这些信息以包括多样的资源。 例如 CPU 百分比。
大多数日志查询使用DateTime运算符将值now与当前时间进行比较,并返回一小时。 若要了解如何构建基于日志的警报,请参阅基于容器见解创建日志警报。
AKS 警报规则
下表列出了 AKS 的一些建议警报规则。 这些警报只是示例。 可以为 AKS 监视数据引用中列出的任何指标、日志条目或活动日志条目设置警报。
| 条件 | 说明 |
|---|---|
| CPU 使用率百分比>95 | 当所有节点的平均 CPU 使用率超过阈值时发出警报。 |
| 内存工作集百分比>100 | 当所有节点的平均工作集超过阈值时发出警报。 |
顾问建议
如果在资源操作期间出现严重情况或即将发生变化,则门户中的“概述”页面上会显示一个警报。
可以在监控下的顾问建议中找到警报的详细信息和建议的修复措施。 在正常操作期间,不会显示任何顾问建议。
有关 Azure 顾问的详细信息,请参阅 Azure 顾问概述。
注意
如果你正在创建或运行在你的服务上运行的应用程序,Azure Monitor application insights 可能会提供更多类型的警报。
AKS 节点网络指标监视
版本和启用要求:在 Kubernetes 版本 1.29 及更高版本中,默认为所有已启用 Azure Monitor 的群集启用节点网络指标。 对于早期 Kubernetes 版本,必须通过群集配置手动启用网络监视。 此功能要求在群集中配置 Azure Monitor 或 Container insights(容器洞察)。
节点网络指标对于维护正常运行且性能良好的 Kubernetes 群集至关重要。 通过收集和分析有关网络流量的数据,您可以获取有关群集操作的宝贵见解,并识别潜在问题,以便在它们导致中断或性能损失之前进行解决。
默认情况下启用以下节点网络指标,并按节点聚合。 所有指标都包含标签群集和实例(节点名称)。 可以使用 Azure 托管 Prometheus>Kubernetes>网络>群集下的托管 Grafana 仪表板轻松查看这些指标。
AKS 节点网络指标(按数据平面类型)
所有指标都包含以下标签:
cluster-
instance(节点名称)
OS 支持和限制:对于 Cilium 数据平面方案,容器网络可观测性功能仅为 Linux 节点池提供指标。 当前,容器网络可观测性指标不受 Windows 支持。 确保群集具有 Linux 节点池,以实现完整的 Cilium 指标可用性。
对于 Cilium 数据平面方案,容器网络可观测性功能仅为 Linux 提供指标。 当前,容器网络可观测性指标不受 Windows 支持。
Cilium 公开容器网络可观测性使用的多个指标:
| 指标名称 | 说明 | 额外的标签 | Linux | Windows操作系统 |
|---|---|---|---|---|
cilium_forward_count_total |
转发数据包总数 | direction |
已支持 ✅ | 支持 ❌ |
cilium_forward_bytes_total |
已转发总字节数 | direction |
已支持 ✅ | 支持 ❌ |
cilium_drop_count_total |
丢弃数据包总数 |
direction、reason |
已支持 ✅ | 支持 ❌ |
cilium_drop_bytes_total |
丢弃字节总数 |
direction、reason |
已支持 ✅ | 支持 ❌ |
相关内容
- 有关为 AKS 创建的指标、日志和其他重要值的参考,请参阅 AKS 监视数据参考。
- 有关监视 Azure 资源的常规详细信息,请参阅 使用 Azure Monitor 监视 Azure 资源。
- 有关完整 Kubernetes 堆栈的详细监视,请参阅 使用 Azure 服务和云本机工具监视 Kubernetes 群集。
- 有关从 Kubernetes 群集收集指标数据,请参阅 Azure Monitor 中 Prometheus 的托管服务。
- 有关收集 Kubernetes 群集中的日志,请参阅 用于 Kubernetes 监视的 Azure Monitor 功能。
- 有关数据可视化,请参阅 Azure 工作簿和在 Grafana 中监视 Azure 服务。