本文逐步介绍如何使用 Azure Toolkit for IntelliJ 中的 HDInsight 工具来运行 Spark 失败调试应用程序。
先决条件
Oracle Java 开发工具包。 本教程使用 Java 版本 8.0.202。
IntelliJ IDEA。 本文使用 IntelliJ IDEA Community 2019.1.3。
Azure Toolkit for IntelliJ。 请参阅安装 Azure Toolkit for IntelliJ。
连接到 HDInsight 群集。 请参阅连接到 HDInsight 群集。
Azure 存储资源管理器下载。 请参阅下载 Azure 存储资源管理器。
使用调试模板创建项目
创建 spark2.3.2 项目以继续失败调试,并使用此文档中的失败任务调试示例文件。
打开 IntelliJ IDEA。 打开“新建项目”窗口。
a. 在左窗格中选择“Azure Spark/HDInsight”。
b. 从主窗口中选择“Spark 项目和失败任务调试示例(预览)(Scala)”。
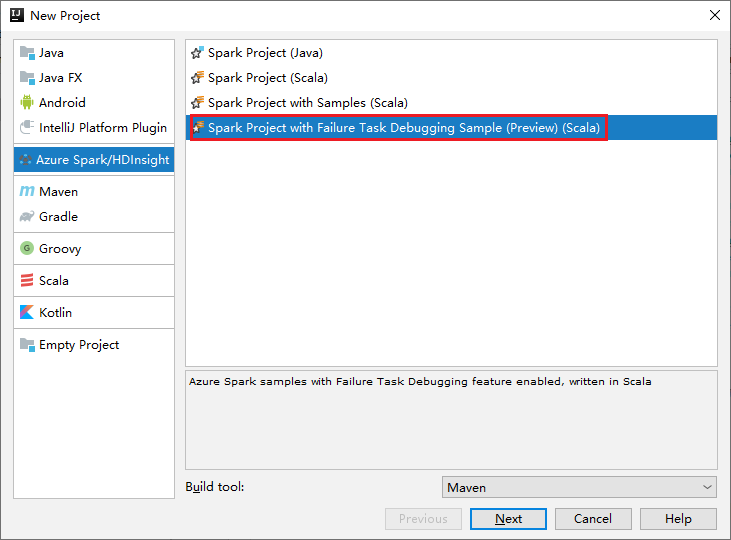
c. 选择“下一步”。
在“新建项目”窗口中执行以下步骤:
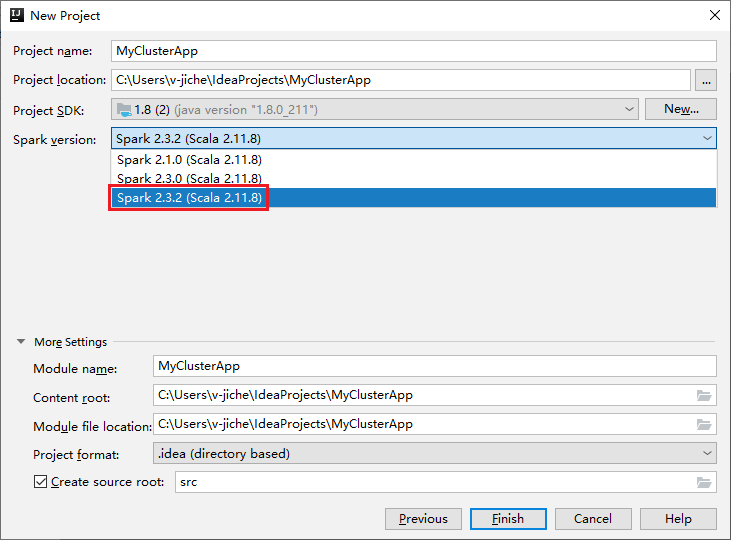
a. 输入项目名称和项目位置。
b. 在“项目 SDK”下拉列表中,选择适用于 Spark 2.3.2 群集的 Java 1.8。
c. 在“Spark 版本”下拉列表中,选择“Spark 2.3.2(Scala 2.11.8)”。
d. 选择“完成”。
选择 src>main>scala 打开项目中的代码。 此示例使用 AgeMean_Div() 脚本。
在 HDInsight 群集中运行 Spark Scala/Java 应用程序
执行以下步骤,创建一个 Spark Scala/Java 应用程序,然后在 Spark 群集中运行该应用程序:
单击“添加配置”,打开“运行/调试配置”窗口。

在“运行/调试配置”对话框中,选择加号 ()。 然后选择“HDInsight 上的 Apache Spark”选项。
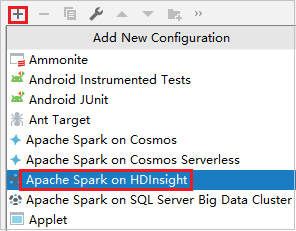
切换到“在群集中远程运行”选项卡。为“名称”、“Spark 群集” 和“Main 类名”输入信息。 工具支持使用“执行器”进行调试。 numExecutors,默认值为 5,设置的值最好不要大于 3。 若要减少运行次数,可以将 spark.yarn.maxAppAttempts 添加到“作业配置”中并将值设置为 1。 单击“确定”按钮,保存配置。
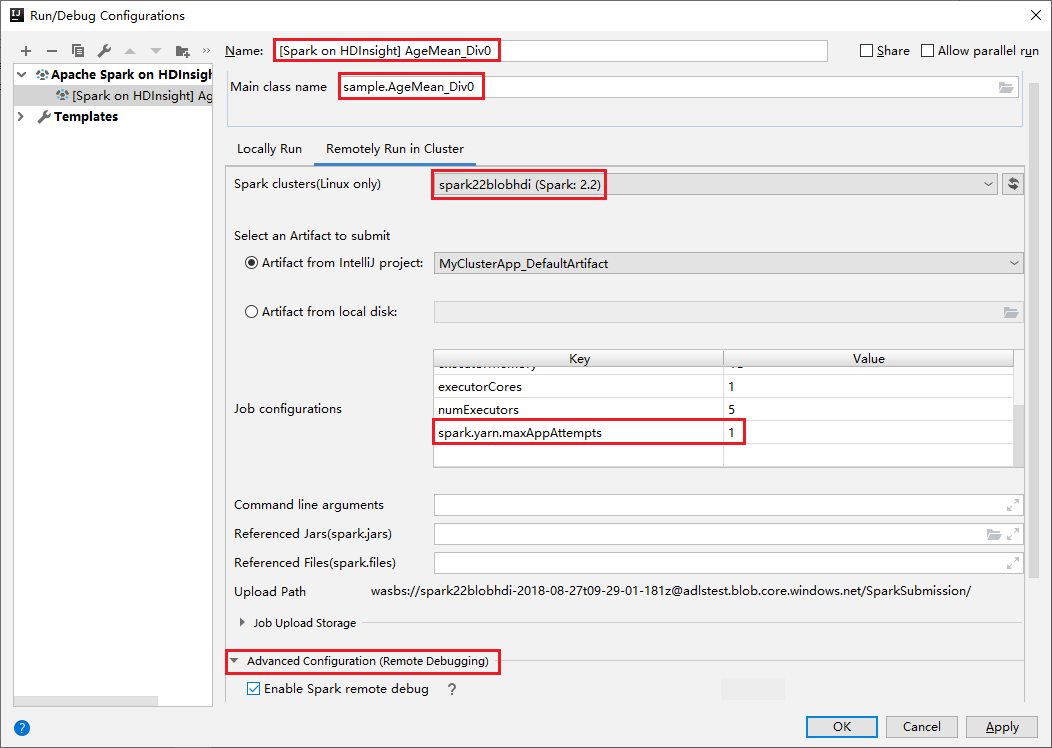
现已使用提供的名称保存配置。 若要查看配置详细信息,请选择配置名称。 若要进行更改,请选择“编辑配置”。
完成配置设置后,可以针对远程群集运行项目。

可以在输出窗口中查看应用程序 ID。

下载已失败作业的配置文件
如果作业提交失败,可以将已失败作业的配置文件下载到本地计算机进行进一步的调试。
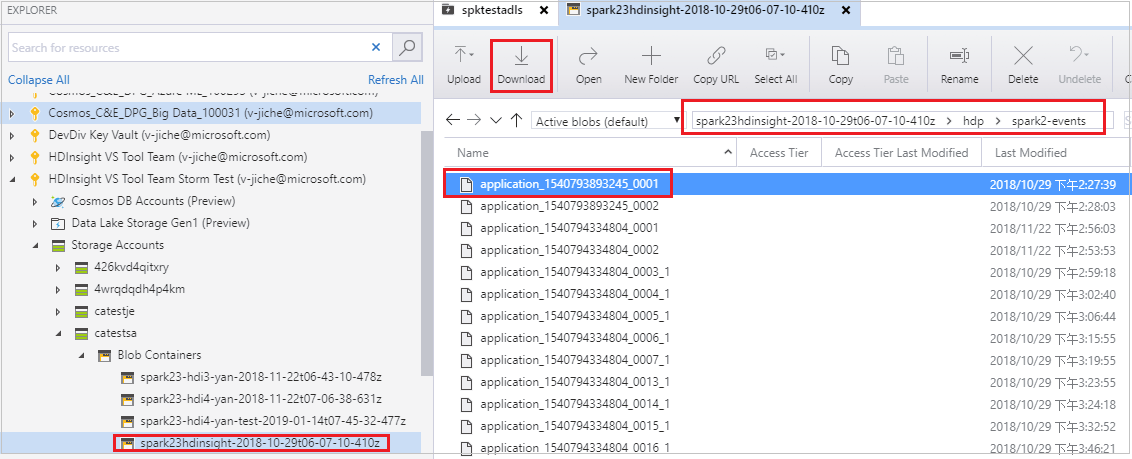
打开 Azure 存储资源管理器,找到已失败作业所在群集的 HDInsight 帐户,将已失败作业的资源从相应的位置 (\hdp\spark2-events\.spark-failures\application ID<) 下载到本地文件夹。“活动”窗口将显示下载进度。
配置本地调试环境并在失败时进行调试
打开原始项目或创建新项目,并将其与原始源代码关联。目前仅支持 spark2.3.2 版本进行失败调试。
在 IntelliJ IDEA 中,创建一个 Spark 失败调试配置文件,从以前下载的已失败作业的资源中选择与“Spark 作业失败上下文位置”字段对应的 FTD 文件。

单击工具栏中的本地运行按钮,错误就会显示在“运行”窗口中。
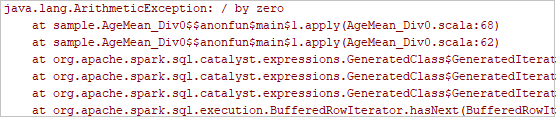
按日志指示设置断点,然后单击本地调试按钮进行本地调试,就像 IntelliJ 中的正常 Scala/Java 项目一样。
调试后,如果项目成功完成,则可将已失败作业重新提交到 Spark on HDInsight 群集。
后续步骤
方案
- Apache Spark 与 BI:使用 HDInsight 中的 Spark 和 BI 工具进行交互式数据分析
- Apache Spark 与机器学习:通过 HDInsight 中的 Spark 使用 HVAC 数据分析建筑物温度
- Apache Spark 与机器学习:使用 HDInsight 中的 Spark 预测食品检查结果
- 使用 HDInsight 中的 Apache Spark 分析网站日志
创建和运行应用程序
工具和扩展
- 使用 Azure Toolkit for IntelliJ 为 HDInsight 群集创建 Apache Spark 应用程序
- 使用 Azure Toolkit for IntelliJ 通过 VPN 远程调试 Apache Spark 应用程序
- 使用 Azure Toolkit for Eclipse 中的 HDInsight 工具创建 Apache Spark 应用程序
- 在 HDInsight 上的 Apache Spark 群集中使用 Apache Zeppelin 笔记本
- 在 HDInsight 的 Apache Spark 群集中可用于 Jupyter Notebook 的内核
- 将外部包与 Jupyter Notebook 配合使用
- Install Jupyter on your computer and connect to an HDInsight Spark cluster(在计算机上安装 Jupyter 并连接到 HDInsight Spark 群集)