你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
本文帮助你了解 Azure 数据工厂和 Azure Synapse Analytics 中的管道和活动,并帮助你利用它们为数据移动和数据处理方案构造端到端数据驱动工作流。
Overview
一个数据工厂或 Synapse 工作区可以有一个或多个管道。 “管道”是共同执行一项任务的活动的逻辑分组。 例如,管道可以包含一组活动,这些活动引入和清除日志数据,然后启动映射数据流以分析日志数据。 可以通过管道将活动作为一个集来管理,而非单独管理每个活动。 可以部署和计划管道,而不需单独对活动进行操作。
管道中的活动定义对数据执行的操作。 例如,可使用复制活动将数据从 SQL Server 复制到 Azure Blob 存储。 然后,使用数据流活动或 Databricks Notebook 活动来处理数据并将数据从 Blob 存储转换为 Azure Synapse Analytics 池,在此池的基础上构建商业智能报表解决方案。
Azure 数据工厂和 Azure Synapse Analytics 支持三组活动:数据移动活动、数据转换活动和控制活动。 每个活动可获取零个或多个输入数据集,并生成一个或多个输出数据集。 下图显示了管道、活动和数据集之间的关系:

输入数据集表示管道中活动的输入,输出数据集表示活动的输出。 数据集可识别不同数据存储(如表、文件、文件夹和文档)中的数据。 创建数据集后,可将其与管道中的活动一起使用。 例如,数据集可以是复制活动或 HDInsightHive 活动的输入/输出数据集。 有关数据集的详细信息,请参阅 Azure 数据工厂中的数据集一文。
Note
每个管道的默认软限制为最多 120 个活动,其中包括容器的内部活动。
数据移动活动
数据工厂中的复制活动可以将数据从源数据存储复制到接收器数据存储。 数据工厂支持本部分中的表中列出的数据存储。 来自任何源的数据都可以写入到任何接收器。
有关详细信息,请参阅复制活动 - 概述一文。
选择某个数据存储即可了解如何将数据复制到该存储,以及如何从该存储复制数据。
Note
如果连接器标记为“预览”,可以试用它并给我们反馈。 若要在解决方案中使用预览版连接器的依赖项,请联系 Azure 支持。
数据转换活动
Azure 数据工厂和 Azure Synapse Analytics 支持以下转换活动,这些活动既可以单独添加,也可以与其他活动关联在一起添加。
有关详细信息,请参阅数据转换活动一文。
| 数据转换活动 | Compute environment |
|---|---|
| Data Flow | Azure 数据工厂托管的 Apache Spark 群集 |
| Azure Function | Azure Functions |
| Hive | HDInsight [Hadoop] |
| Pig | HDInsight [Hadoop] |
| MapReduce | HDInsight [Hadoop] |
| Hadoop Streaming | HDInsight [Hadoop] |
| Spark | HDInsight [Hadoop] |
| Stored Procedure | Azure SQL、Azure Synapse Analytics 或 SQL Server |
| Custom Activity | Azure Batch |
| Databricks Notebook | Azure Databricks |
| Databricks Jar 活动 | Azure Databricks |
| Databricks Python 活动 | Azure Databricks |
| Synapse Notebook 活动 | Azure Synapse Analytics |
控制流活动
支持以下控制流活动:
| Control activity | Description |
|---|---|
| Append Variable | 向现有数组变量中添加值。 |
| Execute Pipeline | 执行管道活动允许数据工厂或 Synapse 管道调用另一个管道。 |
| Filter | 将筛选器表达式应用于输入数组 |
| For Each | ForEach 活动在管道中定义重复的控制流。 此活动用于循环访问集合,并在循环中执行指定的活动。 此活动的循环实现类似于采用编程语言的 Foreach 循环结构。 |
| Get Metadata | GetMetadata 活动可用于检索数据工厂或 Synapse 管道中的任何数据的元数据。 |
| If Condition 活动 | If Condition 可用于基于计算结果为 true 或 false 的条件进行分支。 If Condition 活动可提供 if 语句在编程语言中提供相同的功能。 当条件计算结果为 true 时,它会计算一组活动,当条件计算结果为 false. 时,它会计算另一组活动 |
| Lookup Activity | 查找活动可用于从任何外部源读取或查找记录/表名称/值。 此输出可进一步由后续活动引用。 |
| Set Variable | 设置现有变量的值。 |
| Until Activity | 实现类似于采用编程语言的 Do-Until 循环结构的 Do-Until 循环。 它在循环中将执行一组活动,直到与活动相关联的条件的计算结果为 true。 可以为 Until 活动指定超时值。 |
| Validation Activity | 确保管道仅在存在引用数据集、满足指定条件或已超时时才继续执行。 |
| Wait Activity | 在管道中使用 Wait 活动时,管道将等待指定的时间,然后继续执行后续活动。 |
| Web Activity | Web 活动可用于从管道调用自定义的 REST 终结点。 可以传递数据集和链接服务以供活动使用和访问。 |
| Webhook Activity | 使用 Webhook 活动,调用终结点并传递回调 URL。 管道运行在继续下一个活动之前,等待调用回调。 |
使用 UI 创建管道
若要创建新管道,请导航到“数据工厂工作室”中的“创建者”选项卡(由铅笔图标表示),然后选择加号并从菜单中选择“管道”,然后从子菜单中再次选择“管道”。
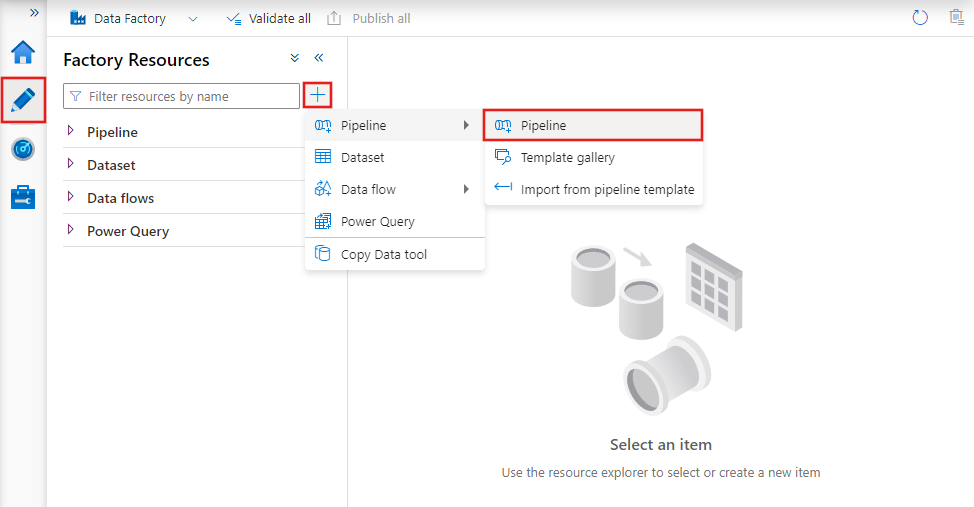
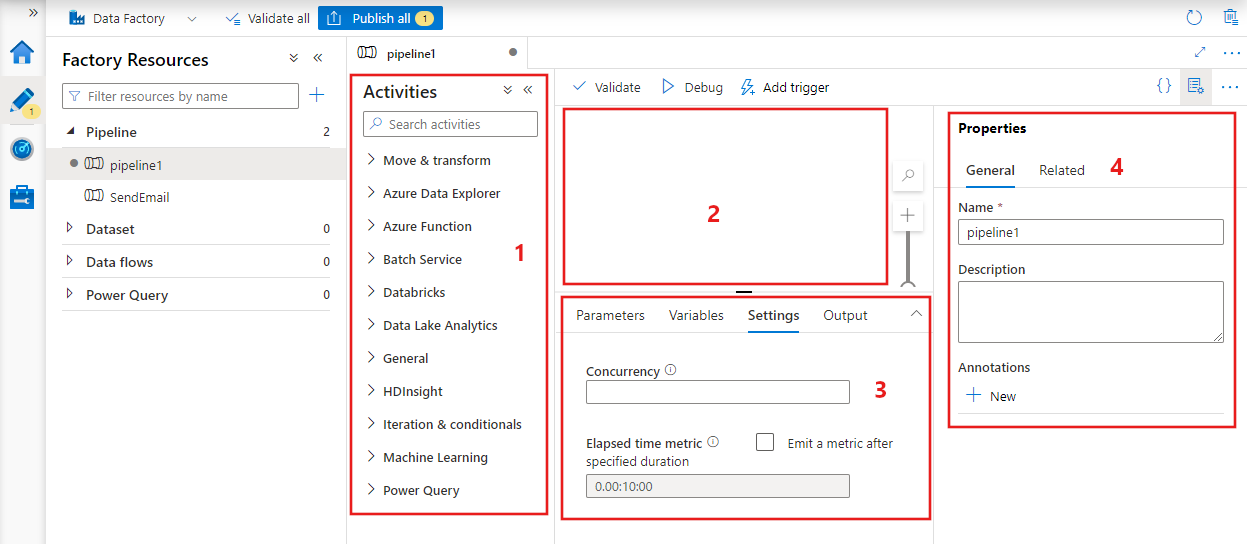
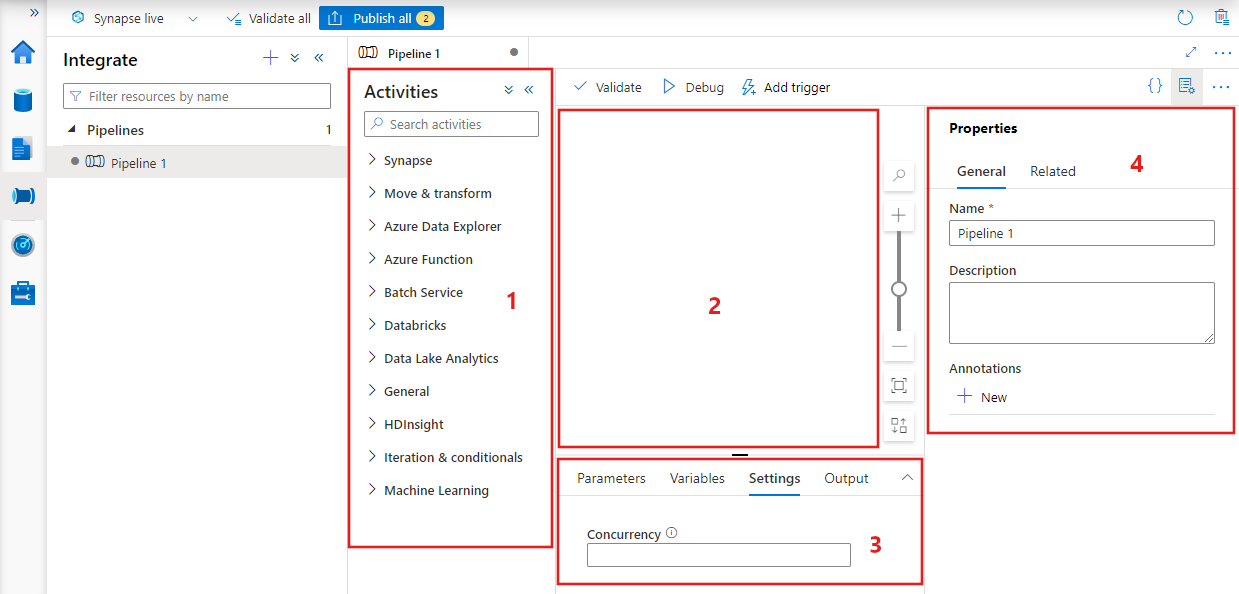
数据工厂显示管道编辑器,可在其中找到以下内容:
- 可在管道中使用的所有活动。
- 管道编辑器画布,其中活动会在添加到管道时显示。
- “管道配置”窗格,包括参数、变量、常规设置和输出。
- 管道属性窗格,用于配置管道名称、可选说明和注释。 此窗格还显示数据工厂中与管道相关的各项内容。
Pipeline JSON
下面介绍如何以 JSON 格式定义管道:
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities":
[
],
"parameters": {
},
"concurrency": <your max pipeline concurrency>,
"annotations": [
]
}
}
| Tag | Description | 类型 | Required |
|---|---|---|---|
| name | 管道的名称。 指定一个名称,它表示管道要执行的操作。
|
String | Yes |
| description | 指定描述管道用途的文本。 | String | No |
| activities | activities 节中可定义有一个或多个活动。 请参阅活动 JSON 一节,以了解有关活动 JSON 元素的详细信息。 | Array | Yes |
| parameters | 参数部分可在在管道内定义一个或多个参数,使你的管道能够灵活地重复使用。 | List | No |
| 并发 | 管道可以具有的最大并发运行数。 默认情况下,没有最大值。 如果达到并发限制,则额外的管道运行将排队,直到较早的管道完成为止 | Number | No |
| annotations | 与管道关联的标记的列表 | Array | No |
Activity JSON
activities 节中可定义有一个或多个活动。 有两种主要类型的活动:执行和控制活动。
Execution activities
执行活动包括数据移动和数据转换活动。 它们具有以下顶级结构:
{
"name": "Execution Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"linkedServiceName": "MyLinkedService",
"policy":
{
},
"dependsOn":
{
}
}
下表描述了活动 JSON 定义中的属性:
| Tag | Description | Required |
|---|---|---|
| name | 活动的名称。 指定一个名称,它表示活动要执行的操作。
|
Yes |
| description | 描述活动用途的文本 | Yes |
| 类型 | 活动的类型。 有关不同的活动类型,请参阅数据移动活动、数据转换活动和控制活动部分。 | Yes |
| linkedServiceName | 活动使用的链接服务的名称。 活动可能需要你指定链接到所需计算环境的链接服务。 |
对于 HDInsight 活动、存储过程活动为“是”。 对其他活动均非必需 |
| typeProperties | typeProperties 部分的属性取决于每个活动类型。 要查看活动的类型属性,请选择链接转到上一节中的活动。 | No |
| 政策 | 影响活动运行时行为的策略。 此属性包括超时和重试行为。 如果未指定,将使用默认值。 有关详细信息,请参阅活动策略部分。 | No |
| dependsOn | 该属性用于定义活动依赖项,以及后续活动对以前活动的依赖方式。 有关详细信息,请参阅活动依赖项 | No |
Activity policy
影响活动运行时行为的策略,提供配置性选项。 活动策略仅对执行活动可用。
活动策略 JSON 定义
{
"name": "MyPipelineName",
"properties": {
"activities": [
{
"name": "MyCopyBlobtoSqlActivity",
"type": "Copy",
"typeProperties": {
...
},
"policy": {
"timeout": "00:10:00",
"retry": 1,
"retryIntervalInSeconds": 60,
"secureOutput": true
}
}
],
"parameters": {
...
}
}
}
| JSON name | Description | Allowed Values | Required |
|---|---|---|---|
| timeout | 指定活动运行的超时。 | Timespan | No. 默认超时为 12 小时,至少为 10 分钟。 |
| 重试 | 最大重试次数 | Integer | No. 默认值为 0 |
| retryIntervalInSeconds | 重试之间的延迟(以秒为单位) | Integer | No. 默认为 30 秒 |
| secureOutput | 当设置为 true 时,来自活动的输出会被视为安全的,不会记录下来进行监视。 | 布尔 | No. 默认值为 false。 |
Control activity
控制活动具有以下顶级结构:
{
"name": "Control Activity Name",
"description": "description",
"type": "<ActivityType>",
"typeProperties":
{
},
"dependsOn":
{
}
}
| Tag | Description | Required |
|---|---|---|
| name | 活动的名称。 指定一个名称,它表示活动要执行的操作。
|
Yes |
| description | 描述活动用途的文本 | Yes |
| 类型 | 活动的类型。 有关不同的活动类型,请参阅数据移动活动、数据转换活动和控制活动部分。 | Yes |
| typeProperties | typeProperties 部分的属性取决于每个活动类型。 要查看活动的类型属性,请选择链接转到上一节中的活动。 | No |
| dependsOn | 该属性用于定义活动依赖项,以及后续活动对以前活动的依赖方式。 有关详细信息,请参阅活动依赖项。 | No |
Activity dependency
活动依赖项定义后续活动对以前活动的依赖方式,确定是否继续执行下一个任务的条件。 活动可能依赖于具有不同依赖项条件的一个或多个以前的活动。
不同依赖项条件有:成功、失败、跳过、完成。
例如,如果管道具有活动 A -> 活动 B,则可能发生的不同情况是:
- 活动 B 对活动 A 具有依赖项条件“成功”:只有活动 A 的最终状态为“成功”,活动 B 才运行
- 活动 B 对活动 A 具有依赖项条件“失败”:只有活动 A 的最终状态为“失败”,活动 B 才运行
- 活动 B 对活动 A 具有依赖项条件“完成”:如果活动 A 的最终状态为“成功”或“失败”,则活动 B 运行
- 活动 B 对活动 A 具有依赖项条件“跳过”:如果活动 A 的最终状态为“跳过”,则活动 B 运行。 在活动 X -> 活动 Y -> 活动 Z 的情况下出现跳过,其中每个活动仅在以前的活动成功后才运行。 如果活动 X 失败,则活动 Y 的状态为“跳过”,因为它从不执行。 类似地,活动 Z 的状态也为“跳过”。
示例:活动 2 是否运行取决于活动 1 是否成功运行
{
"name": "PipelineName",
"properties":
{
"description": "pipeline description",
"activities": [
{
"name": "MyFirstActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
}
},
{
"name": "MySecondActivity",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
},
"dependsOn": [
{
"activity": "MyFirstActivity",
"dependencyConditions": [
"Succeeded"
]
}
]
}
],
"parameters": {
}
}
}
复制管道示例
在以下示例管道中,activities 节有一个 Copy 类型的活动。 在此示例中,复制活动将 Azure Blob 存储中的数据复制到 Azure SQL 数据库中的数据库。
{
"name": "CopyPipeline",
"properties": {
"description": "Copy data from a blob to Azure SQL table",
"activities": [
{
"name": "CopyFromBlobToSQL",
"type": "Copy",
"inputs": [
{
"name": "InputDataset"
}
],
"outputs": [
{
"name": "OutputDataset"
}
],
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
"writeBatchSize": 10000,
"writeBatchTimeout": "60:00:00"
}
},
"policy": {
"retry": 2,
"timeout": "01:00:00"
}
}
]
}
}
请注意以下几点:
- 在 activities 节中,只有一个活动的 type 设置为 Copy。
- 活动的输入设置为 InputDataset,活动的输出设置为 OutputDataset。 有关在 JSON 中定义数据集的信息,请参阅数据集文章。
- 在 typeProperties 节中,BlobSource 指定为源类型,SqlSink 指定为接收器类型。 在数据移动活动部分,选择想要用作源或接收器的数据存储,以了解有关将数据移动到该数据存储或从该数据存储移出的详细信息。
有关创建此管道的完整演练,请参阅快速入门:创建数据工厂。
转换管道示例
在以下示例管道中,activities 部分有一个类型为 HDInsightHive 的活动。 在此示例中,HDInsight Hive 活动通过在 Azure HDInsight Hadoop 群集上运行 Hive 脚本文件,转换 Azure Blob 存储中的数据。
{
"name": "TransformPipeline",
"properties": {
"description": "My first Azure Data Factory pipeline",
"activities": [
{
"type": "HDInsightHive",
"typeProperties": {
"scriptPath": "adfgetstarted/script/partitionweblogs.hql",
"scriptLinkedService": "AzureStorageLinkedService",
"defines": {
"inputtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.chinacloudapi.cn/inputdata",
"partitionedtable": "wasb://adfgetstarted@<storageaccountname>.blob.core.chinacloudapi.cn/partitioneddata"
}
},
"inputs": [
{
"name": "AzureBlobInput"
}
],
"outputs": [
{
"name": "AzureBlobOutput"
}
],
"policy": {
"retry": 3
},
"name": "RunSampleHiveActivity",
"linkedServiceName": "HDInsightOnDemandLinkedService"
}
]
}
}
请注意以下几点:
- 在“活动”部分中,只有一个活动的“类型”设置为“HDInsightHive”。
- Hive 脚本文件 partitionweblogs.hql 存储在 Azure 存储帐户(由 scriptLinkedService 指定,名为 AzureStorageLinkedService)中,以及 容器的 script 文件夹中。
-
defines部分用于指定以配置单元配置值传递到配置单元脚本的运行时设置(例如,${hiveconf:inputtable},${hiveconf:partitionedtable})。
每个转换活动的 typeProperties 节都不同。 若要了解有关转换活动所支持的类型属性的详细信息,请选择数据转换活动中的转换活动。
有关创建此管道的完整演练,请参阅教程:使用 Spark 转换数据。
管道中的多个活动
前两个示例管道中只有一个活动。 可在管道中添加多个活动。 如果在管道中具有多个活动且后续活动不依赖于以前的活动,则活动可能并行运行。
可以使用活动依赖项将两个活动进行链接,以定义后续活动对以前活动的依赖方式,确定是否继续执行下一个任务的条件。 活动可以依赖于具有不同依赖项条件的一个或多个以前的活动。
Scheduling pipelines
管道由触发器计划 触发器有多种类型(让管道按时钟计划触发的计划程序触发器,以及按需触发管道的手动触发器)。 有关触发器的详细信息,请参阅管道执行和触发器一文。
若要使你的触发器启动管道运行,必须包含对触发器定义中的特定管道的管道引用。 管道和触发器具有 n-m 关系。 多个触发器可以启动单个管道,同一个触发器可以启动多个管道。 定义管道后,必须启动触发器,以使其开始触发管道。 有关触发器的详细信息,请参阅管道执行和触发器一文。
例如,假设有一个计划触发器“触发器 A”,我希望使用该触发器启动我的管道“MyCopyPipeline”。 定义该触发器,如以下示例中所示:
触发器 A 定义
{
"name": "TriggerA",
"properties": {
"type": "ScheduleTrigger",
"typeProperties": {
...
}
},
"pipeline": {
"pipelineReference": {
"type": "PipelineReference",
"referenceName": "MyCopyPipeline"
},
"parameters": {
"copySourceName": "FileSource"
}
}
}
}