这些功能和 Azure Databricks 平台的改进已于 2019 年 7 月发布。
注意
在大多数情况下,下面列出的发布日期和内容仅对应于Azure公有云的实际部署。
本文提供 Azure 公有云上的 Azure Databricks 服务演进历程供您参考,其内容可能与由世纪互联运营的 Azure 中的实际部署不一致。
注意
发布分阶段进行。 在初始发布日期后,可能最长需要等待一周,你的 Azure Databricks 帐户才会更新。
即将发生的更改:Databricks 6.0 将不支持 Python 2
预计在即将到来的 Python 2 生命周期结束之后(在 2020 年宣布),Databricks Runtime 6.0 将不支持 Python 2。 更早版本的 Databricks Runtime 将继续支持 Python 2。 我们预计在 2019 年晚些时候发布 Databricks Runtime 6.0。
在池空闲实例上预先加载 Databricks Runtime 版本
2019 年 7 月 30 日 - 8 月 6 日:版本 2.103
现在可以通过选择要在池中空闲实例上加载的 Databricks Runtime 版本来加快以池为支持的群集的启动。 池 UI 上的字段名为预加载 Spark 版本。

自定义集群标签和池标签配合得更加默契
2019 年 7 月 30 日 - 8 月 6 日:版本 2.103
本月初,Azure Databricks 引入了池,这是一组空闲实例,可帮助你快速启动群集。 在原始版本中,池支持的群集继承了池配置中的默认标记和自定义标记,因此无法在群集级别修改这些标记。 现在,你可以配置特定于池支持的群集的自定义标记,并且该群集将应用所有自定义标记,无论这些标记是从池中继承的还是专门分配到该群集的。 添加特定于群集的自定义标记时,其键名不能与从池继承的自定义标记的键名相同(也就是说,不能重写从池继承的自定义标记)。 有关详细信息,请参阅池标记。
MLflow 1.1 带来了多项 UI 和 API 改进
2019 年 7 月 30 日 - 8 月 6 日:版本 2.103
MLflow 1.1 引入了多项新功能来提高 UI 和 API 可用性:
现在,如果运行次数超过 100,可以在“运行概述 UI”中浏览多页的运行信息。 在第 100 次运行之后,单击“加载更多”按钮即可加载随后的 100 次运行。
比较运行 UI 现在提供一个平行坐标图。 通过此绘图,你可以观察 n 维参数集与指标之间的关系。 它将所有运行可视化为根据指标值(如准确度)用颜色编码的线条,并显示每次运行所设定的参数值。

现在可从运行概述 UI 中添加和编辑标记,并在试验搜索视图中查看标记。
新的 MLflowContext API 使你能够使用与 Python API 类似的方式创建和记录运行。 此 API 不同于现有的低级别
MlflowClientAPI,后者仅包装 REST API。现在可以使用 DeleteTag API 从 MLflow 运行中删除标记。
有关详细信息,请参阅 MLflow 1.1 博客文章。 有关功能和修补程序的完整列表,请参阅 MLflow Changelog。
pandas DataFrame 在 Jupyter 中呈现效果一致
2019 年 7 月 30 日 - 8 月 6 日:版本 2.103
现在,当你调用 pandas 数据帧时,它的呈现方式将与在 Jupyter 中的呈现方式相同。
新区域
2019 年 7 月 30 日
目前以下其他区域提供 Azure Databricks:
- 韩国中部
- 南非北部
更新了元存储连接限制
2019 年 7 月 16 日至 23 日:版本 2.102
eastus、eastus2、centralus、westus、westus2、westeurope、northeurope 中的新 Azure Databricks 工作区将具有更高的元存储连接上限 (250)。 现有工作区将继续使用当前的元存储,并且不会受到影响或中断,连接限制依然为 100。
设置对池的权限(公共预览版)
2019 年 7 月 16 日至 23 日:版本 2.102
池 UI 现在支持对可管理池的人员以及可将群集附加到池的人员设置权限。
有关详细信息,请参阅池访问权限。
用于机器学习的 Databricks Runtime 5.5
2019 年 7 月 15 日
Databricks Runtime 5.5 ML 基于 Databricks Runtime 5.5 LTS 构建。 它包含许多常见的机器学习库,包括 TensorFlow、PyTorch、Keras 和 XGBoost,并使用 Horovod 提供分布式 TensorFlow 训练。
此版本包含以下新功能和改进:
- 添加了 MLflow 1.0 Python 包
- 升级了机器学习库
- TensorFlow 已从 1.12.0 升级到 1.13.1
- PyTorch 已从 0.4.1 升级到 1.1.0
- scikit-learn 已从 0.19.1 升级到 0.20.3
- HorovodRunner 的单节点操作
Databricks Runtime 5.5
2019 年 7 月 15 日
Databricks Runtime 5.5 现已推出。 Databricks Runtime 5.5 包括 Apache Spark 2.4.3、已升级的 Python、R、Java 和 Scala 库,以及以下新增功能:
- Azure Databricks 上的 Delta Lake 自动优化 GA
- Azure Databricks 上的 Delta Lake 提升了最小值、最大值和计数聚合查询性能
- 改进后的二进制文件数据源和标量迭代器 pandas UDF 提供更快的模型推理管道(公共预览版)
- R 笔记本中的机密 API
将实例池保持后备状态以快速启动群集(公共预览版)
2019 年 7 月 9 日至 11 日:版本 2.101
为了缩短群集启动时间,Azure Databricks 现在支持将群集附加到空闲实例的预定义池。 附加到池时,群集会从池中分配其驱动节点和工作节点。 如果池中没有足够的空闲资源来满足群集的请求,则池会通过从云提供程序分配新的实例进行扩展。 终止附加的群集后,它使用的实例会返回到池中,可供其他群集重复使用。
当实例在池中处于空闲状态时,Azure Databricks 不会收取 DBU 费用, 实例提供商的账单费用确实适用。 请参阅定价。
有关详细信息,请参阅池配置参考。
Ganglia 指标
2019 年 7 月 9 日至 11 日:版本 2.101
Ganglia 是一种可缩放的分布式监视系统,当前可在 Azure Databricks 群集中使用。 Ganglia 指标有助于监视群集性能和运行状况。 可以从群集详细信息页访问 Ganglia 指标:
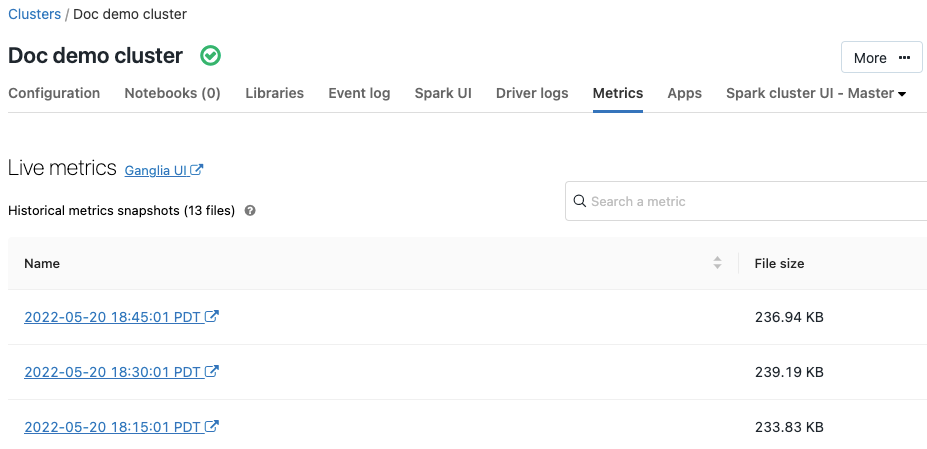
有关使用和配置指标的详细信息,请参阅 Ganglia 指标。
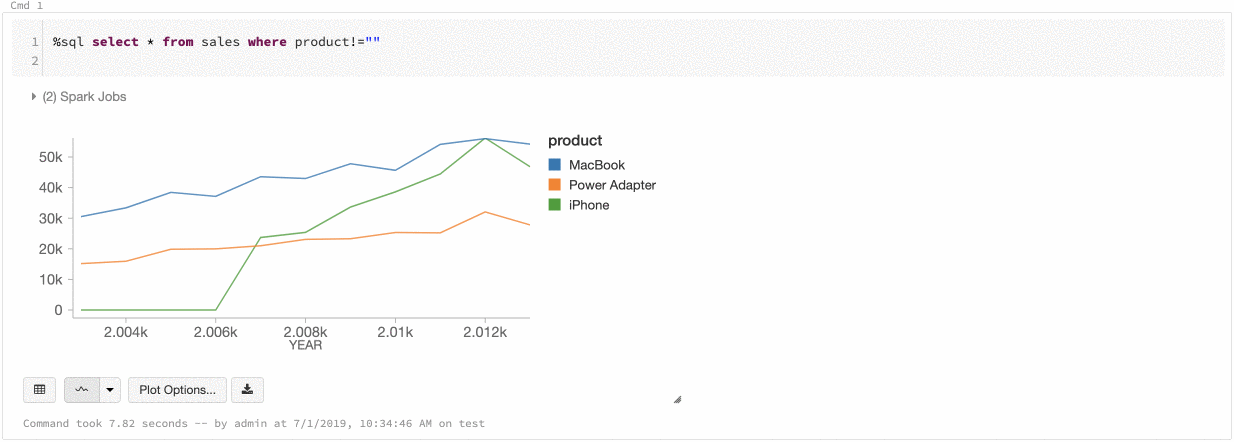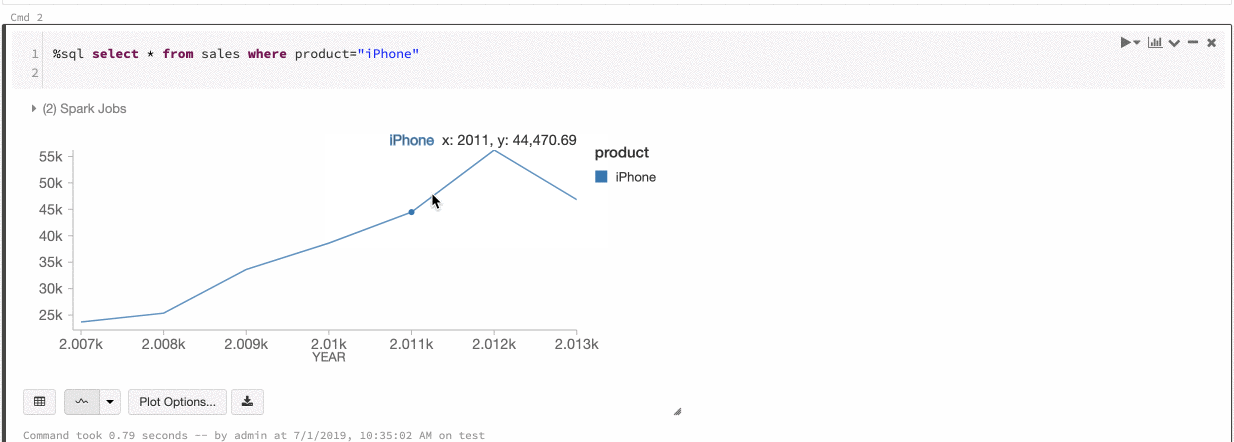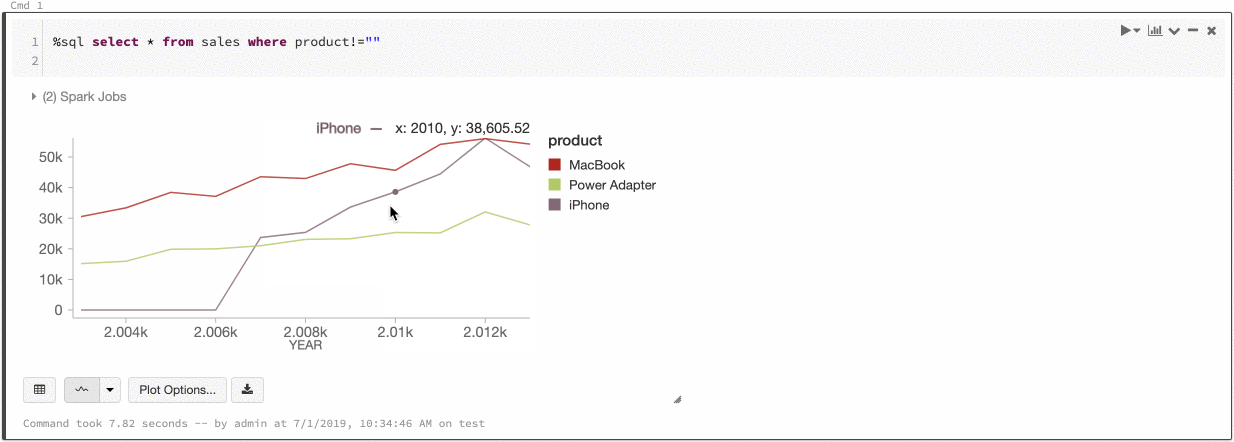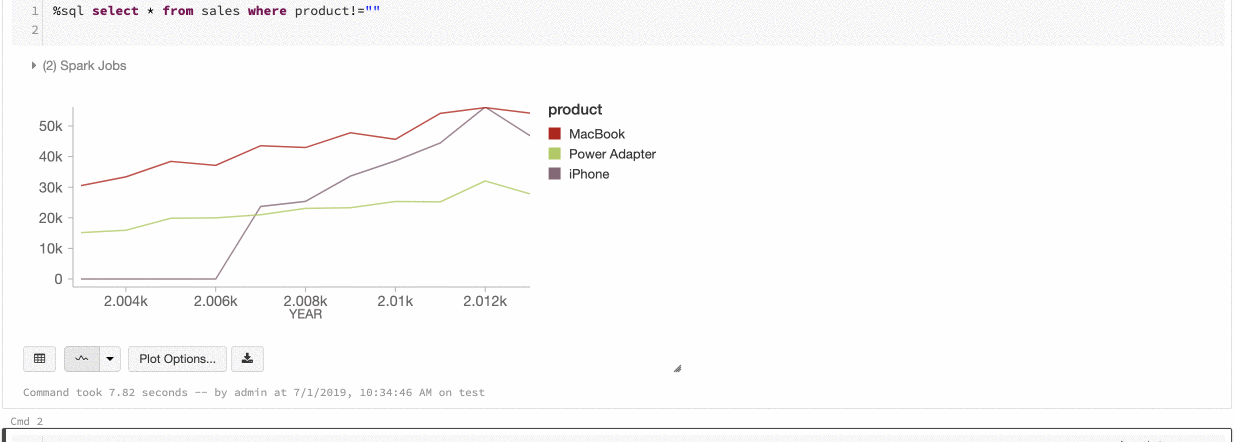
全局系列的颜色
2019 年 7 月 9 日至 11 日:版本 2.101
现在可以指定某个系列的颜色在笔记本中的所有图表中应保持一致。 请参阅图表之间的颜色一致性。