这些功能和 Azure Databricks 平台的改进已于 2019 年 10 月发布。
注意
在大多数情况下,下面列出的发布日期和内容仅对应于Azure公有云的实际部署。
本文提供 Azure 公有云上的 Azure Databricks 服务演进历程供您参考,其内容可能与由世纪互联运营的 Azure 中的实际部署不一致。
注意
发布分阶段进行。 在初始发布日期后,可能最长需要等待一周,你的 Azure Databricks 帐户才会更新。
已移到 Azure 事件中心的可支持性指标
2019 年 10 月 22-29 日
用于支持 Azure Databricks 监视群集运行状况的可支持性指标已从 Azure Blob 存储迁移到事件中心终结点。 这使 Azure Databricks 可以通过较低的延迟响应来解决客户事件。 对于 VNet 注入工作区,我们已将额外的规则添加到 EventHub 服务终结点的网络安全组。 详细信息可在 部署 Azure Databricks 到 Azure 虚拟网络(VNet 注入) 表中找到。 如果要继续使用服务,不需要执行任何操作。
有关按区域列出的 Azure Databricks 可支持性指标事件中心终结点的列表,请参阅元存储、项目 Blob 存储、系统表存储、日志 Blob 存储和事件中心终结点 IP 地址。
适用于标准群集和 Scala 的 Azure Data Lake Storage 凭据直通身份验证已正式发布
2019 年 10 月 22 - 29 日:版本 3.5
适用于 Databricks Runtime 5.5 及以上版本的标准群集的 Python、SQL 和 Scala 的 凭证直通,以及适用于 Databricks Runtime 6.0 及以上版本的 SparkR 均已正式可用。 请参阅为标准群集启用 Azure Data Lake Storage 凭据直通身份验证。
用于基因组学的 Databricks Runtime 6.1 正式版
2019 年 10 月 22 日
用于基因组学的 Databricks Runtime 6.1 已正式发布。
用于机器学习的 Databricks Runtime 6.1 正式版
2019 年 10 月 22 日
Databricks Runtime 6.1 ML 已正式发布。 它包括对 GPU 群集的支持和以下机器学习库的升级:
- TensorFlow 到 1.14.0
- PyTorch 到 1.2.0
- Torchvision 升级至 0.4.0
- MLflow 到 1.3.0
MLflow API 调用现在受速率限制
2019 年 10 月 22 - 29 日:版本 3.5
为了确保在负载较高的情况下也能提供高质量的服务,Azure Databricks 现在正针对所有 MLflow API 调用强制实施 API 速率限制。 限制是按帐户设置的,以确保共享工作区的所有组织具有公平的使用量和高可用性。
具有自动重试的 MLflow 客户端在 MLflow 1.3.0 中可用,并且位于 Databricks Runtime 6.1 ML 中。 建议所有客户切换到最新的 MLflow 客户端版本。
有关详细信息,请参阅试验 API。
用于快速启动群集的实例池已正式发布
2019 年 10 月 22 - 29 日:版本 3.5
支持将群集附加到空闲实例的预定义池中的 Azure Databricks 功能现已正式发布。
当实例在池中处于空闲状态时,Azure Databricks 不会收取 DBU 费用, 实例提供商的计费适用。 请参阅定价。
有关详细信息,请参阅池配置参考。
Databricks Runtime 6.1 正式版
2019 年 10 月 16 日
Databricks Runtime 6.1 为 Delta Lake 引入了几项增强功能:
- 轻松将表转换为 Delta Lake 格式
- 适用于 Delta 表的 Python API(公共预览版)
- 默认情况下启用动态文件修剪 (DFP)
Databricks Runtime 6.1 还消除了对凭据透传支持中的几个限制。
注意
从6.1 版本开始,Databricks Runtime 仅支持 CPU 群集。 如果要使用 GPU 群集,必须使用 Databricks Runtime ML。
用于基因组学的 Databricks Runtime 6.0 正式发布版
2019 年 10 月 16 日
用于基因组学的 Databricks Runtime(Databricks Runtime 基因组学)是为处理基因组和生物医学数据而优化的 Databricks Runtime 变体。 从版本 6.0 开始,用于基因组学的 Databricks Runtime 现已正式发布。
将 Azure Databricks 工作区部署到您自己的虚拟网络(也称为 VNet 注入)的能力现已达到正式版(GA)状态。
2019 年 10 月 9 日
我们很高兴地宣布正式推出将 Azure Databricks 工作区部署到你自己的虚拟网络的功能(也称为 VNet 注入)。 此选项适用于具有以下要求的用户:需要网络自定义,因此不希望使用以标准方式部署 Azure Databricks 工作区时创建的默认 VNet。 利用 VNet 注入,可以:
- 使用服务终结点以更安全的方式将 Azure Databricks 连接到其他 Azure 服务(如 Azure 存储)。
- 连接到本地数据源以与 Azure Databricks 配合使用,以充分利用用户定义的路由。
- 将 Azure Databricks 连接到网络虚拟设备以检查所有出站流量并根据允许和拒绝规则执行操作。
- 将 Azure Databricks 配置为使用自定义 DNS。
- 配置网络安全组 (NSG) 规则以指定出口流量限制。
- 在现有虚拟网络中部署 Azure Databricks 群集。
通过将 Azure Databricks 部署到自己的虚拟网络中,还可以利用灵活的 CIDR 范围(虚拟网络的 CIDR 范围在 /16-/24 之间,子网最高可达 /26)。
使用 Azure 门户 UI 进行配置非常快捷:在创建工作区时,只需选择“在虚拟网络中部署 Azure Databricks 工作区”,然后选择虚拟网络,并提供两个子网的 CIDR 范围。 Azure Databricks 使用两个新的子网和网络安全组来更新虚拟网络,允许入站和出站的子网流量访问,并将工作区部署到更新后的虚拟网络。
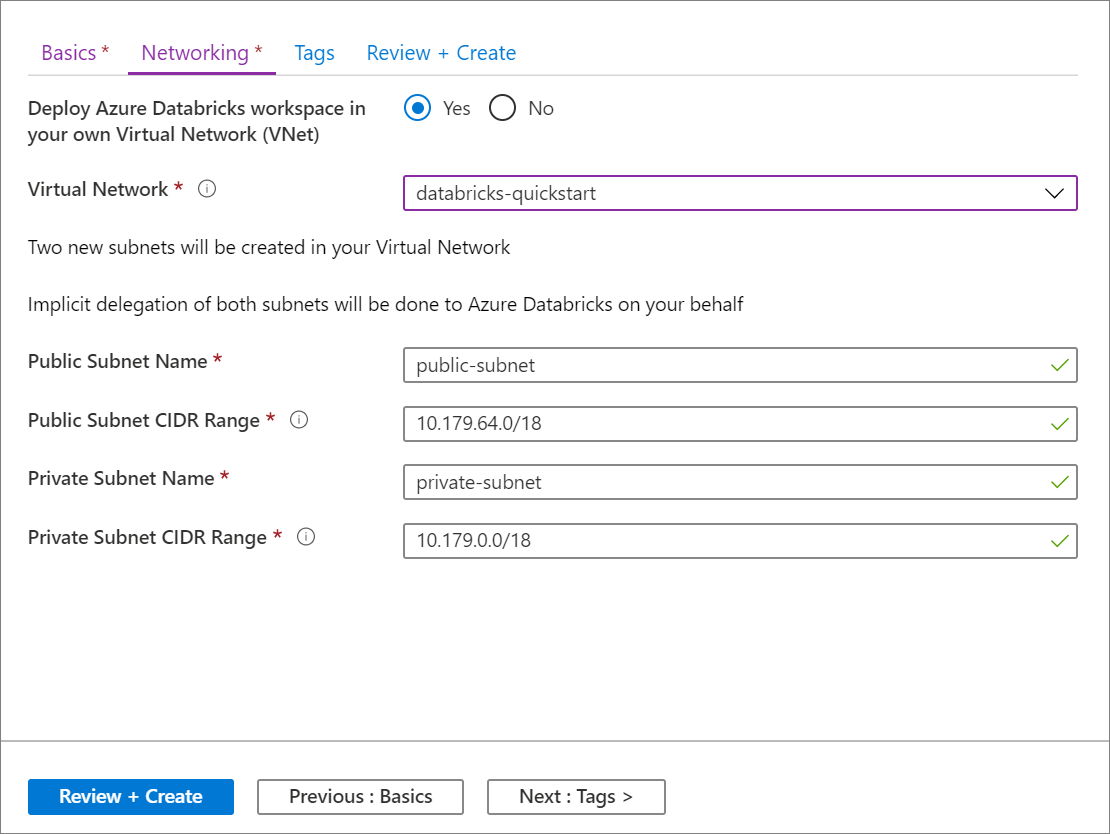
如果希望自行配置用于 VNet 注入的虚拟网络(例如,你想要使用现有子网、使用现有网络安全组,或者创建自己的安全规则),则可以使用 Azure Databricks 提供的 ARM 模板(而不是门户 UI)。
注意
如果你使用过 VNet 注入预览版,则必须在 2020 年 1 月 31 日前将预览版工作区升级到正式版本,才能继续获取支持。
有关详细信息,请参阅在 Azure 虚拟网络中部署 Azure Databricks(VNet 注入)和将 Azure Databricks 工作区连接到本地网络。
非管理员 Azure Databricks 用户可以使用 SCIM API 读取用户和组的名称与 ID
2019 年 10 月 8 - 15 日:版本 3.4
非管理员用户现在可以调用Groups API的“获取用户”和“获取组”终结点,以仅读取用户和组的显示名称和 ID。 所有其他 SCIM API 操作仍需要管理员访问权限。
工作区 API 返回笔记本和文件夹对象 ID
2019 年 10 月 8 - 15 日:版本 3.4
get-status 和 list 这两个 Workspace API 的终结点现在返回笔记本和文件夹对象 ID,使您能够在其他 API 调用中引用这些对象。
Databricks Runtime 6.0 ML 正式版
2019 年 10 月 4 日
Databricks Runtime 6.0 ML 包括以下更新:
- MLflow
- 新的 MLflow 试验 Spark 数据源提供了一种用于加载 MLflow 试验运行数据的标准 API。
- 已添加 MLflow Java 客户端
- MLflow 现已提升为顶层库
- Hyperopt GA - 自公共预览以来,显著的改进包括支持在 Spark 工作节点上进行 MLflow 日志记录、对 PySpark 广播变量的正确处理,以及使用 Hyperopt 进行模型选择的新指南。
- 已升级 Horovod 和 MLflow 库以及 Anaconda 发行版。
注意
此版本仅支持 CPU 群集。
新区域:巴西南部和法国中部
2019 年 10 月 1 日
Azure Databricks 现已在巴西南部(圣保罗州)和法国中部(巴黎)推出。
Databricks Runtime 6.0 正式版
2019 年 10 月 1 日
Databricks Runtime 6.0 引入了许多库升级和新功能,其中包括:
- 用于 Delta Lake DML 命令的新 Scala 和 Java API,以及清空和历史记录实用工具命令。
- 增强的 DBFS FUSE 客户端,支持在模型训练过程中更快、更可靠地进行读取和写入。
- 支持在每个笔记本单元内使用多个 matplotlib 绘图。
- 更新到 Python 3.7,以及更新的 numpy、pandas、matplotlib 和其他库。
- 停用 Python 2 支持。
注意
此版本仅支持 CPU 群集。